Section 4.4 Méthodes de réduction spectrales
Subsection 4.4.1 Méthode EigenMaps
La méthode centrale de cette approche s'appelle la méthode EigenMaps. On considère donc \(\mathcal{M}\) une variété riemannienne. On rappelle comme précédemment que notre objectif de trouver un représentant dans \(\mathbb{R}^{m}\) de chaque point \(x\in \mathcal{M}\subset\mathbb{R}^d\) ce qui revient d'un certain point de vue a déterminer une carte locale associée à notre variété. Soit une carte locale
On considère que ces cartes locales \(\phi_x=[\phi_1(x),...,\phi_d(x)]\) sont linéaires ou proches. On nomme \(\phi\) la fonction \(y=f(x)\) globale (que l'ont suppose deux fois différentiables) qui va approcher nos cartes locales. L'idée fondamentale comme précédemment est de préserver les distances. Si deux points sont proches sur la variété, on veut que leurs coordonnées locales restent proches dans \(\mathbb{R}^m\text{.}\) Cest une propriété raisonnable a attendre des cartes locales sur une variété régulière. On souhaite donc que:
On rappelle que le gradient \(\nabla f\) est un élément de l'espace tangent \(T_x \mathcal{M}\text{,}\) tel que pour \(\forall v\in T_x \mathcal{M}\) on est \(f(v)= g_x(\nabla f(x), v)\) avec \(g_x\) la métrique riemannienne. On définit \(\gamma(t)\) la courbe géodésique avec \(\gamma(0)=x_1\) et \(\gamma(l)=x_2\) paramétrisée par la longueur \(l\text{.}\) On rappelle que \(\dot{\gamma}(t)\) est un vecteur tangent à \(\gamma(t)\text{.}\) On utilise tout cela pour avoir:
On utilise la correspondance de la métrique avec le produit scalaire dans l'espace tangent. Puis on utilise Cauchy-Schwartz pour obtenir
Puisque la courbe géodésique est de longueur \(l\) alors \(\parallel \dot{\gamma}(t) \parallel_2 =l\) et donc par un développement de Taylor dans l'espace tangent on obtient
et donc
ce qui est équivalent à
On voit donc que \(\parallel\nabla f(x_1) \parallel_2 \) donne une estimation d’à quel point la transformation préserve les distances/voisinages.
le calcul formel précédent montre que si on veut que \(f\) soit une isométrie entre la variété (avec sa distance géodésique associée) et l'espace \(\mathbb{R}^m\) il faut alors construire un plongement tel que le gradient de ce plongement soit petit. On cherche dnc une transformation \(f\) tel que
Cela revient à
avec \(\Delta_{\mathcal{M}}\) l'opérateur de Laplace Beltrami associé à la variété. Lorsqu'on on ordonne les valeurs propres de façon croissante pour le Laplacian comme pour l'opérateur de Laplace -Beltrami cela revient a ordonner les vecteurs propres du mode le moins oscillant sur la variété aux modes les plus oscillants. Les vecteurs propres de l'opérateur de Laplace Beltrami comme la base de Fourier associée à la variété. 
Subsection 4.4.2 Algorithme et limite de la méthode
Ce résultat justifie l'approche précédente (il existe une façon de le faire en utilisant des arguments discret) puisque si nos points sont portés par une variété le Laplacien sur graphe converge vers l'opérateur de Laplace Beltrami et donc les vecteurs propres du Laplacien sur graphe convergent vers ceux de Laplace Beltrami. En projetant sur cette base on peut espérer trouver une transformation qui minimise le gradient au sens de la variété. On en déduit l'algorithme suivant:
Pour la méthode Eigenmaps on utilise en général une autre approche pour calculer la matrice du Laplacien que directement le graphe des plus proches voisins. L'idée est d'utiliser le lien entre l'équation de la chaleur sur une variété et l'opérateur de Laplce Beltrami. Puisque l'opérateur \(\Delta \) et un opérateur autoadjoint positif on peut écrire un semi-groupe
L'action de ce semi-groupe peut s'écrire avec un noyau de green:
On va pas rentrer dans les détails, mais noyau de Green peut s'approcher par
On sait que \(A_t=e^{-t \Delta}\text{,}\) par un développement limité très formel autour de zéro on voit que
Maintenant on va discretiser cette formule sur un certains nombres de points \(x_i\) puis observer que si on définit les poids et le degré de la manière suivante
avec \(O_i\) un ensemble de voisins de \(x_i\text{,}\) c'est exactement équivalent à \(\Delta f =(D-W)f\text{.}\) On va donc construire notre matrice du Laplacien en suivant ses définitions. On obtient l'algorithme suivant.
Algorithm 4.30. Algorithme Eigenmaps.
On calcule le graphe des plus proches voisins au sens du rayon,
On calcule les matrices de degré \(D\) et de poids \(W\) (symétrisée) avec les définitions (4.12), (4.13),
On calcule la matrice de Laplacien sur le graphe,
On calcule les \(m\) premiers vecteurs propres,
On obtient à chaque point du graphe \(i\) un vecteur de taille \(m\) avec les ième composantes de chaque vecteur.

Sur la figure Figure 4.31 on voit que la méthode Eigenmaps donne des résultats correct, mais moins bon que la méthode ISOMAP par exemple (qui est cependant beaucoup plus coûteuse). En effet elle a tendance a concentrer les points sur une courbe (en dimension 1) plutôt que sur un plan alors qu'on fait une projection dans \(\mathbb{R}^2\text{.}\) Comme pour eigenmaps la qualité dépend aussi du nombre de voisins choisis.
Subsection 4.4.3 Limite de la méthode
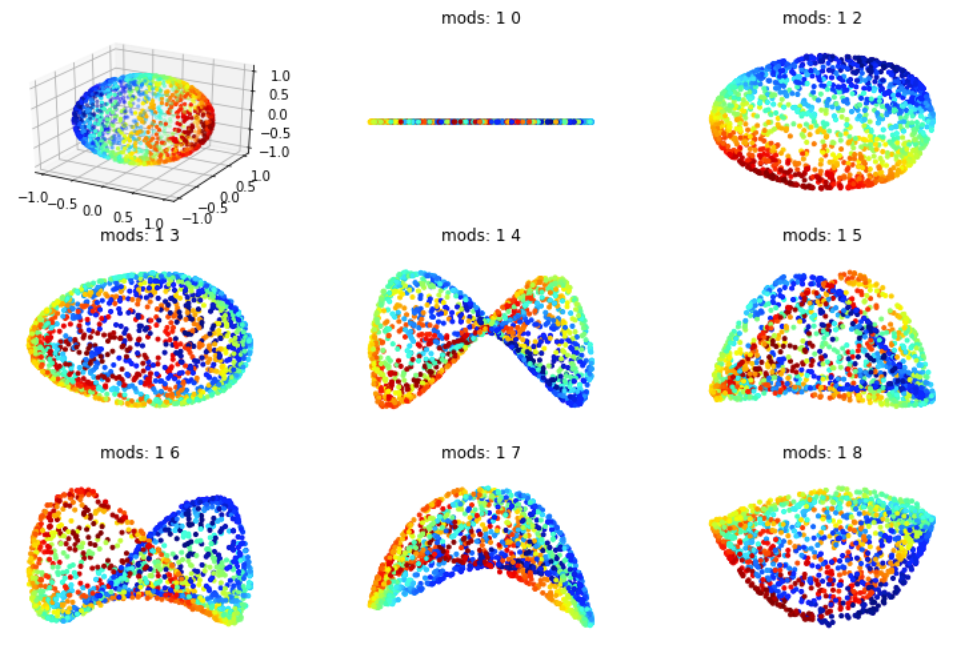
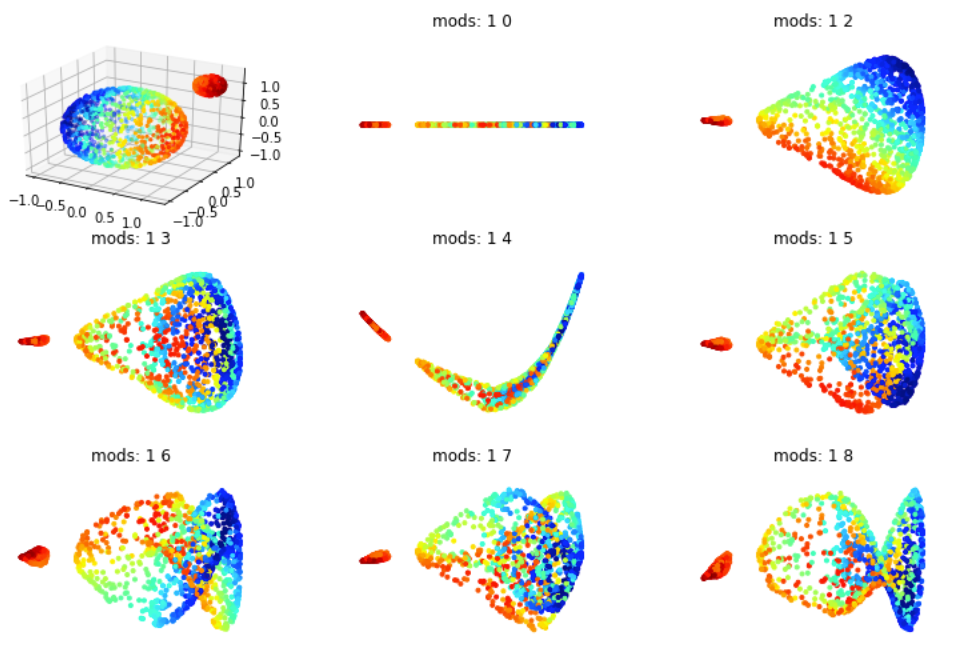
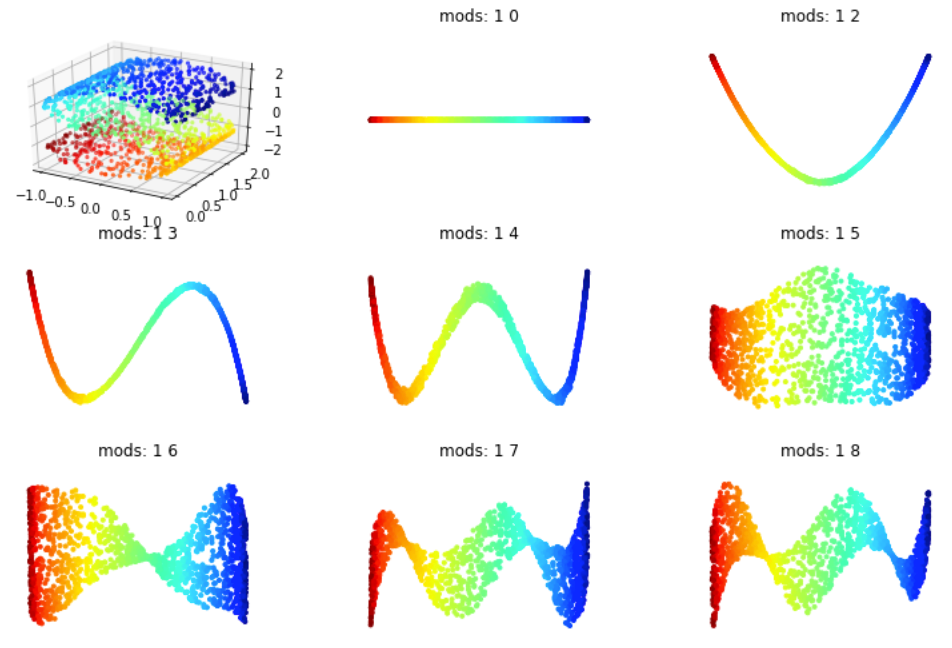
On retrouve donc le phénomène de concentration de la variété lors de la projection. Cependant on voit que si on prend des vecteurs propres un peu plus grands on peut parfois remédier partiellement à cela. En faite se phénomène se comprend très bien sûr le cas d'un plan. Si on prend un carré et qu'on calcul ces deux vecteurs premiers vecteurs propres on va projeter notre fonction sur:
car il s'agit des modes associés aux plus basses fréquences \(\frac{2\pi}{L}\text{.}\) Maintenant supposons que l'on considère un rectangle de longueur \(L_x\) 3 fois plus grande que la largeur \(L_y\) alors les deux plus basses fréquences vont être \(\frac{2\pi}{L_x}\) et \(\frac{4\pi}{L_x}\) et donc les premiers vecteurs propres sont:
on va donc projeter nos données sur deux fonctions propres dépendante de \(x\) et indépendante de \(y\text{.}\) Cela va faireperdre l'aspect 2D de la variété lors de la projection. Pour éviter cela il faudrait prendre le premier vecteur propre selon \(y\text{.}\) A priori la méthode standard EigenMaps ne permet pas cela car il n'est pas évident de l'identifier sans connaitre la variété cible.
Subsection 4.4.4 Variantes de la méthode
../../../../CodeFrench.html#SciML2../../../../CodeFrench.html#SciML2../../../../CodeFrench.html#SciML2../../../../CodeFrench.html#SciML2