Section 5.3 Réseaux récurrents et transformeur
Subsection 5.3.1 Réseaux récurrents pour les séries temporelles
Jusqu’à présent les réseaux permettant plus de traiter des problèmes de traitement du signal ou structurés en espace. Maintenant on va introduire les réseaux utilisés pour les problèmes temporels notamment pour la prédiction de la série de données temporelles.
Le problème qu'on regarde est le suivant: on a a notre disposition des données temporelles du type \((x_1,...,x_t)\) et l'ont souhaite construire la loi de probabilité suivante:
On se place donc dans cadre "non Markovien" ou on ne dépend pas que du temps précédent. On pourrait traiter cela avec un réseau classique type MPC. Dans ce cas on aurait un réseau \(f_{\theta}(x_1,...,x_{t-1})\) qui prédirait la valeur de \(x_t\text{.}\) Cependant ce réseau ne pourrait pas s'appliquer à tous les temps. En effet dans ce cas la taille de l'entrée est variable. Cette solution n'est donc pas adaptée en règle générale. Il existe plusieurs solutions pour éviter cela:
Le fenêtrage: on va supposer que le passé lointain compte peut et donc que notre réseau va estimer la probabilité \(\mathbb{P}(x_t\mid x_{t-1},...x_{t-m})\) dans ce cas l'entrée est fixe et on peut utiliser un réseau classique de type MPC.
Le modèle lalent: on va construire une variable supplémentaire qui va porté au cours du temps de l'information issue des états précédents. Si on nomme cet état caché: \(h_t\) on chercher a construire la loi \(\mathbb{P}(x_t\mid x_{t-1},h_{t-1})\text{.}\)
Il faut savoir qu'il existe un autre problème d'apprentissage sur les séquences. On peut aussi avoir envie d'estimer non pas la loi conditionnelle (5.8) mais la loi jointe:
Ce genre de probabilité peut être estimée à l'aide des probabilités conditionnelles comme le montre la formule:
Les réseaux classiques pour le problème (5.8) utilise l'approche de type latent.
Un réseau récurrent a pour but de transformer une séquence \((x_1,...,x_n)\) en une autre séquence \((y_1,...,y_n)\) en pouvant traiter de séquence de taille variable. Pour tenir compte du passé, on utilise en pratique les modèles latents. On se donne des séquences d'entrée \((x_1,...,x_n)\) et de sortie \((y_1,...,y_n)\text{.}\) Un réseau récurrent est un réseau de neurones qui va approcher une fonction de la forme: avec \(x_t\) un élément de notre série temporelle d'entrée, \(h_t\) un vecteur latent et \(y_t\) un élément de notre série de sortie. Soit une entrée \(x_t \in\mathbb{R}^{d_i}\) et une sortie \(y_t \in\mathbb{R}^{d_o}\text{.}\) Un réseau de Elman est un réseau récurrent à deux couches: avec \(d_h\) la dimension des états latents, avec des matrices de poids \(W_h \in\mathcal{M}_{d_h,d_i}\text{,}\) \(U_h \in\mathcal{M}_{d_h,d_h}\) et \(W_y \in\mathcal{M}_{d_o,d_h}\text{,}\) des biais \(b_h \in \mathbb{R}^{d_h},b_y \in \mathbb{R}^{d_o}\) et \(\sigma_h()\text{,}\) \(\sigma_y()\) des fonctions d'activations. Soit une entrée \(x_t \in\mathbb{R}^{d_i}\) et une sortie \(y_t \in\mathbb{R}^{d_o}\text{.}\) Un réseau de Elman est un réseau récurrent à deux couches: avec \(d_h\) la dimension des états latents, avec des matrices de poids \(W_h \in\mathcal{M}_{d_h,d_i}\text{,}\) \(U_h \in\mathcal{M}_{d_h,d_h}\) et \(W_y \in\mathcal{M}_{d_o,d_h}\text{,}\) des biais \(b_h \in \mathbb{R}^{d_h},b_y \in \mathbb{R}^{d_o}\) et \(\sigma_h()\text{,}\) \(\sigma_y()\) des fonctions d'activations. Un réseau récurrent profond à \(K\) couche est réseau du type: avec \(f_{\theta_h}\) une couche du type Elman par exemple. La fonction de coût pour les réseaux récurrents est donnée par avec \(T\) la taille de la série.
Définition 5.46. Réseau récurrent.
Définition 5.47. Réseau recurrent de Elman.
Définition 5.48. Réseau recurred de Jordan.
Définition 5.49.
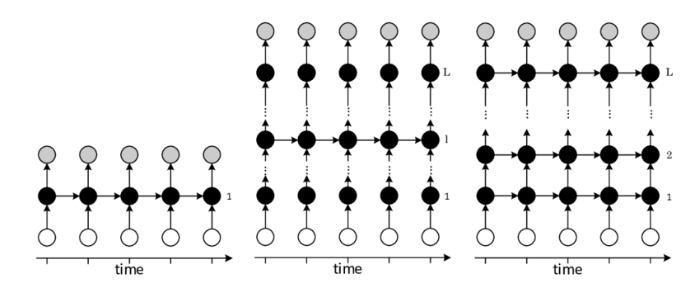
Définition 5.51.
avec \(\theta_h=(W_h,U_h,b_h)\text{.}\) En appliquant encore une fois la dérivée des fonctions composées:
Maintenant on peut expliciter \(\frac{\partial h_{j+1}}{\partial h_{j}}\text{,}\) par un calcul simple on obtient dans le cas d'un réseau d'Elman par exemple:
par conséquent dans le calcul de nos gradients globaux on va avoir le produit:
Ce type de quantité peut facilement s'annuler pour \(t\) grand car il suffit que l'un des termes dans le produit s'annule. De plus on peut même montrer que cela finira toujours par tendre vers zéro ou l'infini quand la série en temps est longue. En effet, si la valeur propre dominante de \(U_h\) est plus grande que 1 cela finira par exploser et si la valeur propre dominante \(U_h\) est plus petite que 1 ça finira par disparaître. Cela s'explique par le fait que le terme \(\sigma_h^{'}\left(W_h x_{j+1}+U_h h_{j}+b_h\right)\) est toujours plus petit que 1 pour les fonctions d'activation type sigmoïde ou tanh.
Subsubsection 5.3.1.1 Réseau de type LSTM
Les réseaux LSTM pour "long short time memory" ont été proposés pour régler les problèmes de disparition de gradient. L'idée est de remplacer une couche simple de RNN (qui construit l'état latent en fonction du précédent et de l'élément courant de la la séquence) par une couche un peu plus compliquée qui va avoir une mémoire à court terme et une mémoire à long terme. Dans un réseau récurrent on a une porte d'entée qui effectue une combinaison linéaire de l'état latent et de l'entrée avant d'appliquer une fonction d'activation. Dans les réseaux LTSM on utilise trois portes d'entrées qui régule le flux d'information et deux types de sorties ou états. Soit un état caché \(h_t \in[-1,1]^d\) et le vecteur d'état \(c_t\in[-1,1]^d \text{.}\) Une cellule LSTM: avec \(W_f,W_i,W_o,W_c \in \mathcal{M}_{d,d}(\mathbb{R})\) les matrices de poids, \(b_f,b_i,b_o,b_c \in \mathcal{M}_{d,d}(\mathbb{R})\) les vecteurs de poids, \(\sigma_g\) la fonction sigmoïde et \(\sigma_h\) la fonction tangente hyperbolique.
Définition 5.52. Cellule LTSM.
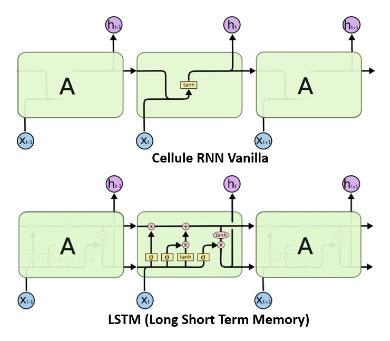
avec \(\theta=(\theta_h,\theta_c)=(W_{f,i,o,c},U_{f,i,o,c},b_{f,i,o,c})\text{.}\) Comme précédemment
Et donc l'enjeu va se retrouver dans le calcul \(\frac{\partial c_{j+1}}{\partial c_{j}}\text{.}\)
On a donc
ce que donne
Deux mécanismes vont aider à ce que le produit des gradients \(\frac{\partial c_{j+1}}{\partial c_{j}}\) ne converge pas vers zéro. D'abord notre gradient est la somme de 4 termes par conséquent pour l'annuler il faut annuler les 4 termes ce qui est nettement plus difficile donc il est difficile d'annuler ce produit \(\left(\prod_{j=i}^t \frac{\partial c_{j+1}}{\partial c_{j}}\right)\) en annulant un des termes. Évidemment comme pour les RNN on pourrait aussi avoir ce produit qui temps vers zéro ou l'infini lorsque \(t\) grand. Si on commence à converger vers zéro, il est toujours possible d'ajuster la valeur de \(f_t\) (ou des autres portes) pour qu'elles soient plus élevées afin d'amener la valeur du gradient plus proche de 1, ce qui empêche les gradients de disparaître trop rapidement.
Les bonnes propriétés de stabilité des réseaux LTSM (on peut évidemment enchaîner les couches LSTM) comme pour les réseaux RNN font de ses réseaux parmi les plus utilisés.
Subsubsection 5.3.1.2 Réseau GRU
Il existe un autre type de réseau récurrent avec des bonnes prorpriétés de stabilité. On parle du réseau GRU qui se rapproche du cas LSTM. Soit un état caché \(h_t \in[-1,1]^d\text{.}\) Une cellule GRU est donnée par: avec \(W_z,W_r,W_h\in \mathcal{M}_{d,d}(\mathbb{R})\) les matrices de poids, \(b_z,b_r,b_h \in \mathcal{M}_{d,d}(\mathbb{R})\) les vecteurs de poids, \(\sigma_g\) la fonction sigmoïde et \(\sigma_h\) la fonction tangente hyperbolique.
Définition 5.54. Cellule GRU.
Le capacité et les propriétés de stabilité des réseaux GRU sont similaires à celle des réseaux de type LSTM.
Subsection 5.3.2 Réseaux de neurones et attention
Les "tansformers" sont un type de réseaux de neurones introduits en 2017 pour le traitement du langage naturel (traduction) puis étendus au problème de traitement du signal et donc des fonctions spatiales. Afin d'expliquer les idées centrales, on va se placer dans le cadre du traitement de langage pour introduire les outils.
Subsubsection 5.3.2.1 Mécanisme d'attention
La stratégie utilisée avant les transformer pour la traduction s'appelle le modèle SeqtoSeq. Il s'agit d'un modèle qui va transformer une séquence (par exemple une phrase en français) en une autre séquence (par exemple en anglais). Si on se donne comme séquence d'entrée \((x_1,...,x_n)\) et \((y_1,...,y_n)\) comme séquence de sortie alors l'objectif est de construire la loi de probabilité:
On se donne deux réseaux: l'encodeur et le décodeur. Le rôle de l'encodeur :
est de transformer la séquence en un vecteur \(h\) de longueur fixe (appelé vecteur de contexte) et le rôle du décodeur
est de prédire la suite de la séquence de sortie en utilisant les éléments précédents de la séquence et du vecteur de contexte. Ce processus est détaillé sur l'image Figure 5.55. 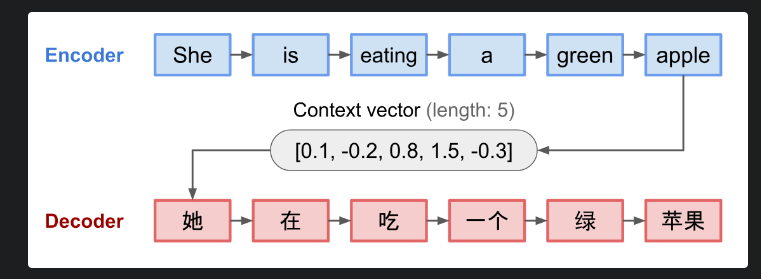
en appliquant un softmax dont on apprendra les poids \((\mathbf{w}_j)_{1 \leq j \leq K}\text{:}\)
Ensuite on maximise le maximum de vraisemblance et cela revient a minimiser l'entropie croisée classique en classification multi-classe.
Dans un premier temps, on a beaucoup utiliser pour l'encodeur et le décodeur des réseaux de type LSTM/GRU, etc. Un problème est que, si la séquence d'entrée est longue, le fait que le vecteur de contexte soit de taille fixe fait que les informations situées à la fin de la séquence vont avoir tendance à avoir un poids trop important dans le vecteur de contexte. Le \mécanisme d'attention à pour but de régler ce problème. Plutôt que de construire un vecteur de contexte unique à partir du résultat de l'encodeur, l'idée de l'attention consiste à créer des raccourcis entre le vecteur de contexte et tous les éléments de la séquence. Les poids associés aux raccourcis sont personnalisables pour chaque élément de sortie. Comme le vecteur de contexte a accès à l'ensemble de la séquence d'entrée, nous n'avons pas à nous soucier de l'oubli. Le première exemple d'attention a été proposé dans [1.18].
Pour l'encodeur on propose d'utiliser une version bi directionnelle d'un RNN. Pour cela on écrit deux RNN qui parcourent les données dans les deux sens
Ensuite on définit un état lalent comme concaténation des deux états \(h_t=[\overrightarrow{h}_t, \overrightarrow{h}_t]\text{.}\) Si, on est état dans un bi-RNN classique on utilisera l'état latent pour calculer la sortie avec la formule:
Maintenant revenons à notre encodeur. L'idée de l'attention est de construire notre vecteur de contexte à partir de l'ensemble des états cachés de la séquence et pas juste le dernier. Avant d'introduire cette construction qui est le coeur des méthodes d'attention on va commencer par définir rapidement le décodeur. Donc le décodeur sera un réseau récurrent classique prenant en compte le vecteur de contexte. Il sera de la forme:
avec \(s_t\) les états cachés du décodeur. Maintenant passons au vecteur de contexte. Pour cela on va donc propose la définition suivant
Cela revient donc a dire que le vecteur de contexte est une combinaison linéaire des états cachés de l'encodeur. Reste à définir les coefficients \(\alpha_{t,i}\text{.}\) L'idée est de construire le coefficient \(\alpha_{t,i}\) de façon à ce qu'il mesure à quel point la sortie \(y_t\) et l'entrée \(x_i\) se correspondre bien ( on parle d'alignement). Pour cela on utilise les états cachés associés à \(y_t\) et \(x_i\)
et le score est donné par une couche simple:
avec \(v_{a}^t, W_a\) des paramètres entraînables. L'ensemble des coefficients \(\alpha_{ti}\) forment une matrice qui mesure l'alignement entre tous les états cachés du décodeur et encodeur et donc entre tous les éléments des séquences. On peut l'interpréter comme une matrice de corrélation entre les éléments des deux séquences. 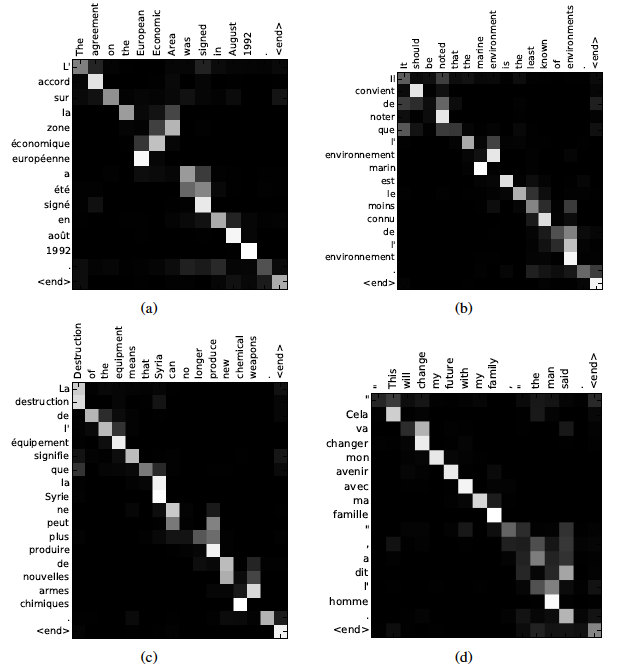
l'attention au contenu: \(score(s_{t-1,h_i})= cosine([s_{t-1},h_i])\text{,}\)
l'attention basée sur le produit scalaire: \(score(s_{t-1,h_i})= \frac{s_{t-1}^t h_i}{\sqrt{n}}\text{,}\)
l'attention dite générale: \(score(s_{t-1,h_i})= s_{t-1}^t W_a h_i\text{,}\) avec \(W_a\) une matrice entraînable.
l'intra-attention que l'ont va détailler un peu par la suite.
Subsubsection 5.3.2.2 Intra-attention et "transformer"
On va maintenant parler de certains mécanisme d'attention particulière qui sont au coeur d'une architecture de réseau très utilisée appelée "transformer". Un mécanisme d'intra-attention est un mécanisme qui met en relation différentes positions d'une même séquence afin de calculer une représentation de cette même séquence. On va donc construire une matrice de corrélation entre les éléments de la séquence. On se donne une entrée \(X\in \mathbb{R}^{n,d}\text{.}\) Soit \(W_Q, W_K, W_V\in \mathbb{R}^{d,d}\) des matrices de poids entraînable. On définit trois quantités: La requète: \(Q=W_q X \) La clé: \(K=W_K X \) La valeur: \(V=W_V X \) L'intra-attention est donnée par On se donne une entrée \(X\in \mathbb{R}^{n,d}\text{.}\) Soit \(W_Q^i, W_K^i, W_V^i\in \mathbb{R}^{d,d}, \quad
\forall i \lt n\) des matrices de poids entraînable. La transformation d'attention multi tête (ici \(m\) tête) est donnée par avec \(W_0\) une matrice de poids entraînables.
Définition 5.57. Auto - Attention.
Définition 5.58. Auto - Attention multi tête.
L’encodeur transforme une séquence d’entrée dans une séquence abstraite qui contient toutes les informations apprises de cette entrée. Le décodeur prend ensuite cette représentation continue et génère étape par étape une sortie unique tout en étant également alimenté par la sortie précédente. ![]()
![]()
Mathématiquement les blocs d' un transformeurs s'écrivent sous la forme suivante. Soit \(\mathbf{x} \in \mathbb{R}^{n \times d}\) alors la transformation \(f_\theta(\mathbf{x})=\mathbf{z}\) est donnée par: Les étapes de normalisation par paquet sont définies par
Définition 5.61. Block d'un transformeur.