Les réseaux de neurones sont une des familles de fonction paramétrée nonlinéaire que l'ont peut utiliser pour faire de l'apprentissage. Elles sont devenues depuis une dizaine d'années très populaires, car ils ont permis d'obtenir des résultats spectaculaires notamment en traitement du signal et en traduction qui sont des problèmes en grandes dimensions.
Subsection5.1.1Réseaux de neurones totalement connectés
Un réseau de neurones est une fonction paramétrique obtenue par composition de fonction simple que l'on va appeler des couches. On parlera de réseaux de neurones profonds quand le nombre de couches sera grand donc quand on obtiendra une fonction par composition d' un grand nombre de fonctions simples.
Définition5.1.Couche.
On appelle une couche la fonction \(L:\bs{x}\in \mathbb{R}^{d_i} \rightarrow \bs{y}\in\mathbb{R}^{d_{i+1}}\) définie par
\begin{equation}
L_{i,i+1}(\bs{x})= \sigma (A \bs{x} + \bs{b})\tag{5.1}
\end{equation}
avec \(A\in \mathcal{M}_{d_i,d_{i+1}}(\mathbb{R})\text{,}\)\(\bs{b}\in \mathbb{R}^{d_{i+1}}\) et \(\sigma()\) une fonction nonlinéaire appliquée terme à terme. On nomme \(\sigma()\)la fonction d'activation. Les coefficients de \(A\) et \(\bs{b}\) sont appelés paramètres entraînables.
Définition5.2.Réseau de neurones totalement connecté.
On appelle un réseau de neurones une fonction paramétrique \(N_{\theta}:\bs{x}\in \mathbb{R}^{d_{in}} \rightarrow \bs{y}\in\mathbb{R}^{d_{o}}\) qui est défini par
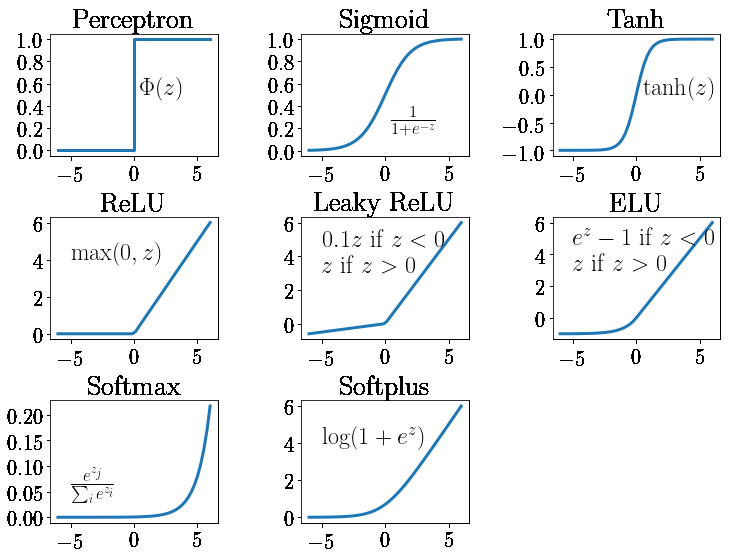
avec \(\theta\) l'ensemble des paramètres entraînables. On appelle un réseau totalement connecté ou Multi-Perceptron un réseau ou les matrices \(A\) sont pleines. On parle d'un Perceptron simple si il y a une seule couche qui va de l'espace d'entrée à celle de sortie. Les couches qui ne concerne pas l'espace de sortie sont appelées couche cachée. Un des ingrédients essentiels des réseaux de neurones est la fonction non linéaire qui intervient entre chaque partie linéaire on parle de fonction d'activation. On va introduire les plus classiques.
Définition5.3.Fonction d'activation ReLu.
On appelle ReLu la fonction de \(\mathbb{R}\) dans \(\mathbb{R}^{+}\)
Il existe beaucoup de variantes ELU, SELU, Leaky RELU qui accepte un peu de passer dans le négatif. Il existe aussi une variante PRELU qui dépend d'un paramètre qui peut lui-même être optimisé. La fonction RELU est une des plus utilisées. Elle n’est cependant pas dérivable en tout point, mais dérivable à gauche et à droite.
Définition5.4.Fonction d'activation Softplus.
On appelle Softplus la fonction \(\mathbb{R}\) dans \(\mathbb{R}^{+}\)
La fonction tangente hyperbolique est aussi une des premières utilisée historiquement.
Figure5.7.Liste de plusieurs fonctions d'activation pour les réseaux de neurones.
Une première question qu'on peut se poser est de savoir si ce choix de fonction paramétrique est un choix raisonnable pour approcher des fonctions. Cette réponse est partiellement donnée par le théorème d'approximation universelle.
Théorème5.8.Théorème de Cybenko.
Soit \(\sigma()\) la fonction sigmoïde. Dans ce cas l'ensemble des réseaux de neurones à une couche cachée est dense dans \(C^{0}([0,1],\mathbb{R})\text{.}\)
Ce théorème nous montre la convergence d'un réseau de neurones vers une fonction donnée quand le nombre de neurones devient plus important. Cependant la constante \(\gamma(f)\) croit exponentiellement avec la dimension d. Ce résultat ne nous permet pas de casser la malédiction de la dimension. Il y a cependant un paramètre qu'on n’a pas exploité c'est la profondeur du réseau (nombre de couches). En pratique il existe des théorèmes montrant qu'il existe des fonctions a une couche cachée approximable avec un nombre exponentiel en fonction de la dimension de neurones qu'on peut approcher par des réseaux a deux couches avec un nombre polynomial (en fonction de \(d\)) de neurones.
Pour le problème de régression introduit dans le chapitre 2 on utilise en général comme couche finale une fonction d'activation linéaire. Pour la classification (catégoriser des données) en deux catégories on utilise fonction d'activation sigmoïde afin d'obtenir une probabilité dans \([0,1]\text{.}\) La classification nous intéresse peu, mais elle permet de fournir des exemples simples de fonctionnement de réseau pour la suite.
Subsection5.1.2Gradient et rétropropagation
Comme vu précédemment une fois qu'on a une fonction paramétrique (réseau de neurones ou autres) on va l'utiliser pour résoudre des problèmes de régression (ou de classification). Pour cela, en général, on se donne une fonction de coût (loss) et on va résoudre le problème de minimisation par une méthode de gradient (stochastique en général). Pour cela il faut être capable de calculer le gradient de cette fonction coût par rapport aux poids. On va voir maintenant comment ce calcul peut s'effectuer pour des réseaux de neurones.
avec \(f_{\theta}\) un réseau de neurones. Comment on calcule le gradient de \(\mathcal{L}(\theta)\) ? On va se donner un réseau à trois couches pour commencer:
On voit que si on calcule le second terme de la somme, on peut réutiliser une partie de ce calcul pour calculer la troisième partie de la somme. Ce genre d'accélération se fait très bien pour des réseaux plus profonds. On va maintenant regarder rapidement ce qui se passe en général.
Gradient réseaux profond.
On se donne un réseau \(n\) couches pour commencer:
avec \(\bs{h}_i\) la sortie de \(f_i\text{.}\) En utilisant de la même façon le gradient d'une composition de fonction on obtient les deux inégalités suivantes:
La combinaison de ces deux relations nous montre que le calcul du gradient par rapport à une couche se calcule avec le gradient de la gauche suivante. Cela nous donne un algorithme qui permet de calculer rapidement le gradient y compris pour des réseaux profonds.
Algorithm5.10.Algorithme de rétropropagation.
On initialise un vecteur \(\bs{G}\) à zéro qui contiendra le gradient final
On calcul \(\nabla_{\bs{h}_n} \mathcal{J}\)
On calcul \(\nabla_{\bs{h}_n} \mathcal{J} \frac{\partial f_{\theta}^n(\bs{h}_{n-1}) }{\partial \theta}\) et on l'ajoute à \(\bs{G}\)
\(\forall i\) de \(n-1\) à 1:
On calcule \(\nabla_{\bs{h}_i} \mathcal{J}\) en multipliant \(\nabla_{\bs{h}_{i+1}} \mathcal{J}\) par la dérivée \(\frac{\partial f_{\theta}^i(\bs{h}_{i}) }{\partial \bs{h}_{i} }. \)
On calcul \(\frac{\partial f_{\theta}^i(\bs{h}_{i-1}) }{\partial \theta } \) et on
Cet algorithme nous permet de calculer le gradient sur une donnée facilement, car dérivée une seule couche est très facile. Pour cela il faut propager l'entrée \(\bs{x}\) dans le réseau afin de calculer l'erreur puis on va retro-propager l'erreur afin de calculer le gradient. En général à partir de là on utilise des algorithmes de type gradient stochastique (on détaillera les plus évolués en fin de section). Avant d'introduire des architectures plus avancées, on va étudier les défauts des réseaux profonds.
Subsection5.1.3Instabilité de gradients
Les résultats théoriques semblent montrer que la profondeur semble être une solution pour améliorer la performance des réseaux. Cependant on va voir que numériquement c'est plus compliqué et et qu'il a fallu pluieurs élements pour utiliser des réseaux profonds qui ont donné de meilleurs résultats in finé. Pour montrer ces problèmes, on va passer par des exemples de classification. Et plus précisément un jeu de données de classification de photos de vêtement. On commence par utiliser une fonction d'activation sigmoïde qui a été le standard au début des réseaux de neurones.
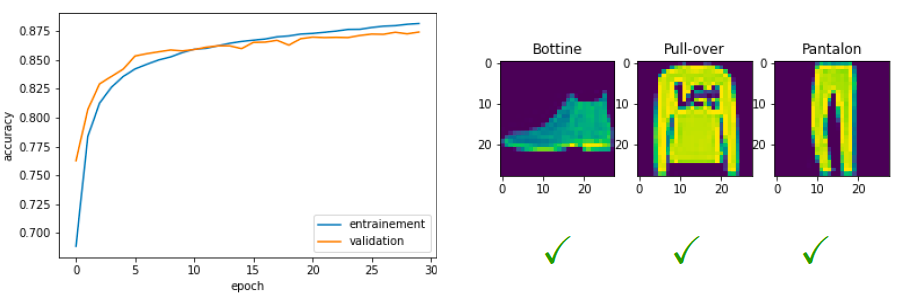
Figure5.11.Jeux de données: vêtements. Résultat d'un entraînement avec un réseau à une couche cachée sigmoïde (30 neurones par couche). Sur la figure Figure 5.11 on voit que l'entraînement se passé bien on arrive à un taux de 87.5% de réussite sur le jeu de validation.
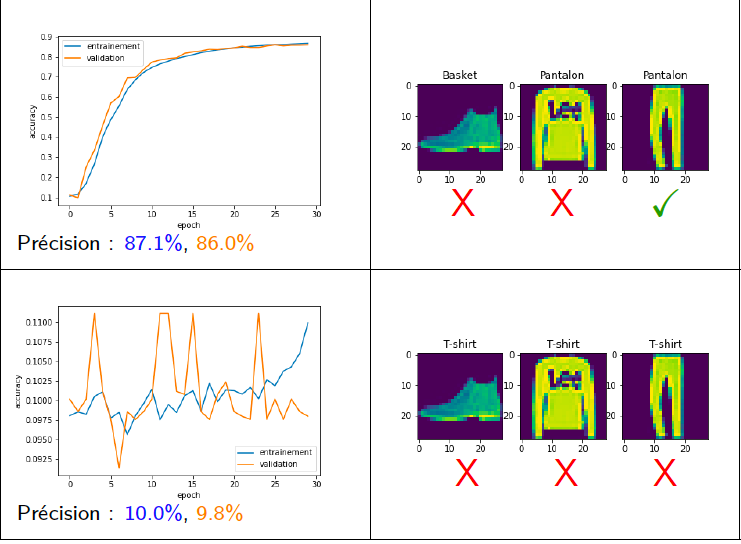
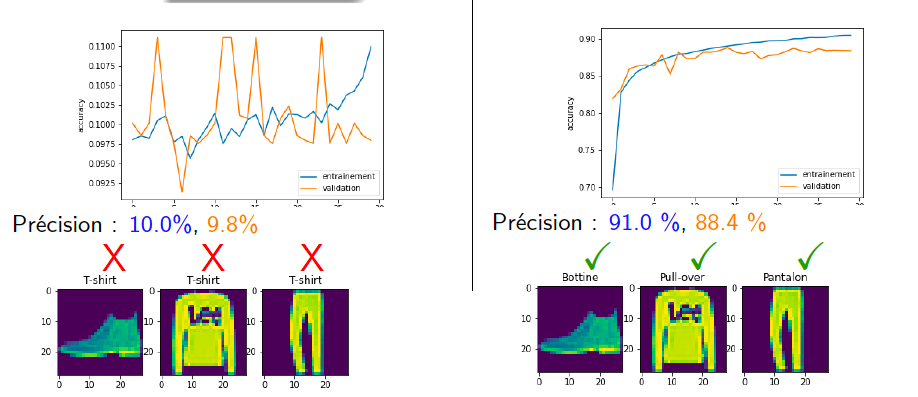
Figure5.12.Jeux de données: vêtements. Résultat d'entraînements avec des réseaux à 4 et 6 couches cachées sigmoïdes (30 neurones par couche). Sur la figure Figure 5.12 on voit que l'on perd un peu de précision avec un réseau à 4 couches cachées (86.0% de réussite sur le jeu de validation). Ici le problème vient d'un convergence plus lente (il y a plus de poids à déterminer) et on pourrait supposer qu'en faisait un peu plus d'époques on arrive a des résultats meilleurs. Par contre dans le cas du réseau à 6 couches l'entraînement se passe très mal et le réseau n'apprend pas du tout.
Pour comprendre ce problème d'apprentissage, revenons à l'algorithme de rétropropagation. On rappelle que pour calculer le gradient \(\nabla_{\bs{h}_i} \mathcal{J}\) en multipliant \(\nabla_{\bs{h}_{i+1}} \mathcal{J}\) par la dérivée \(\frac{\partial f_{\theta}^i(\bs{h}_{i}) }{\partial \bs{h}_{i} }\) par conséquent on a
Imaginons maintenant que chaque dérivée de la composition soit contractante. Si le réseau est profond le gradient va devenir très faible et les poids vont plus vraiment être modifiés. On parle de disparitions de gradient. Imaginons maintenant que chaque dérivée de la composition augmente la norme, si le réseau est profond le gradient va devenir très grand voir dévenir NaN et les poids ne seront plus modifiés. On parle d'explosion de gradient.
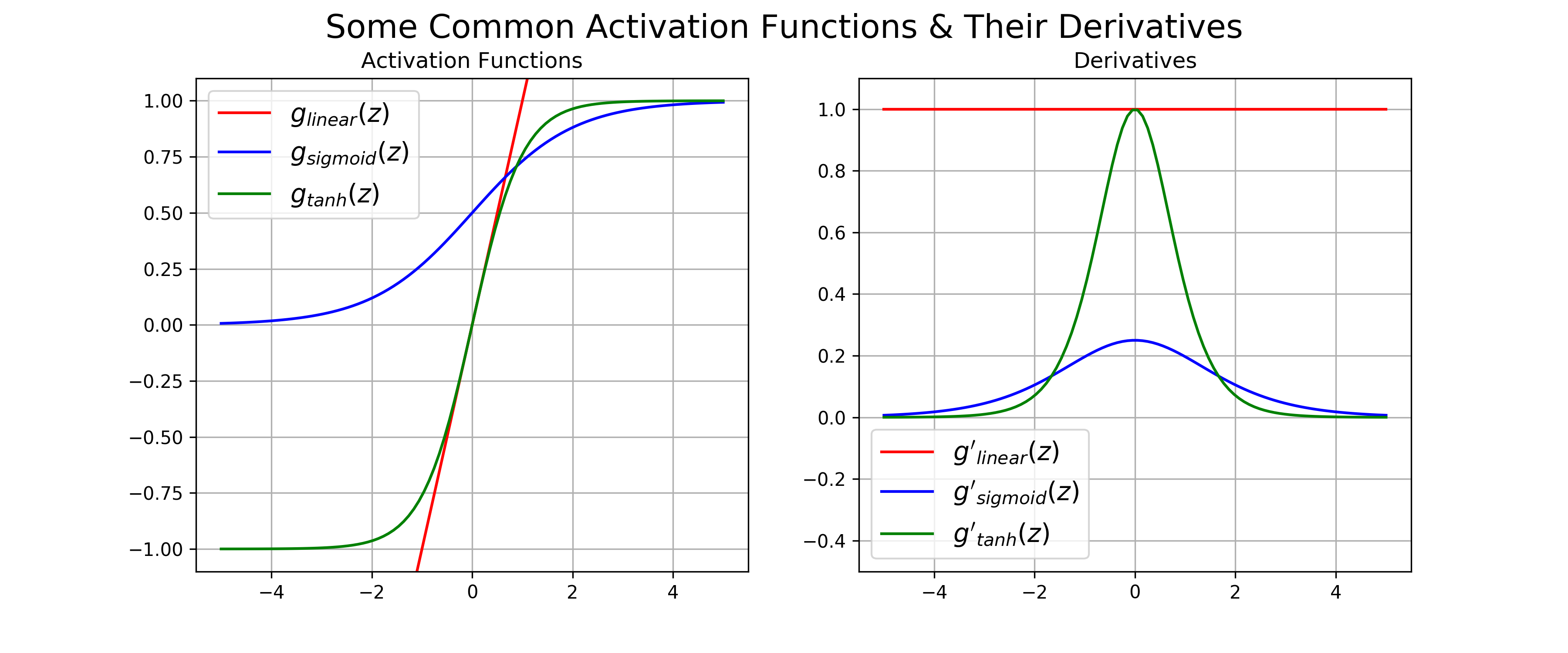
La réussite et la popularité des réseaux de neurones viennent du fait que des méthodes permettent de limiter ce genre de défaut et permettent donc d'utiliser des réseaux profonds. Une première solution a été de modifier l'initialisation aléatoire des poids en ajustant la variance de la loi. Maintenant tous les réseaux utilisent ce genre d'initialisation. La seconde solution a été de modifier la fonction d'activation. Les fonctions sigmoïde ou thanh ont des dérivées qui s'annule assez vite comme on peut le voir sur Figure 5.13.
Figure5.13.Liste de plusieurs fonctions d'activation pour les réseaux de neurones. On voit donc qu'il y a plus de chance d'obtenir des disparitions de gradient avec les fonctions d'activation comme Sigmoid ou la tangente hyperbolique.
Figure5.14.Jeux de données: vêtements. Résultat d'entraînements avec des réseaux à 6 couches caché (30 neurones par couche) avec des fonctions d'activation sigmoïde (gauche) ou ReLu (droite). Sur la figure Figure 5.14 on voit que la on un réseau à 6 couches avec la fonction sigmoïde échoue, le même réseau avec des fonctions ReLu apprend parfaitement et obtient de meilleurs résultats que nos réseaux peu profond. On va continuer a regarder cela sur un autre exemple.
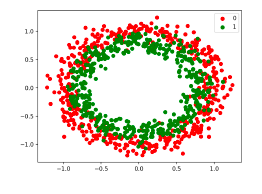
Figure5.15.Jeux de données: cercle. Résultat d'entraînements avec des réseaux à 6 couches caché (30 neurones par couche) avec des fonctions d'activation Tanh (gauche) ou ReLu (droite). En bas réseau Relu à 20 couches. Là encore les résultats au milieu la figure Figure 5.15 montre les meilleures performances de la fonction ReLu avec un réseau à 6 couches. La dernière image en bas elle montre les résultats à 20 couches. Ici l'entraînement n'a pas abouti et on se retrouve donc à nouveau dans cas d'explosion ou de disparition de gradients. Utiliser une fonction ReLu peut donner de meilleurs résultats, mais cela ne suffit pas pour des réseaux très profonds.
Un dernier ingrédient a été proposé. Les réseaux sont entraînés avec des méthodes de type gradient stochastiques. On donne donc des mini-lot de données à chaque étape d'apprentissage dont la variance et la moyenne peuvent être assez éloignées. L'idée est donc d'ajouter une couche avant la fonction d'activation. Cette couche va apprendre à normaliser le mini-lot de données afin d'avoir une variance raisonnable et une moyenne nulle. On parle de normalisation par mini lot.
Définition5.16.Couche de normalisation par lot.
On se donne un batch \(\mathcal{B}= \left\{x_1,....,x_{n_\mathcal{B}} \right\}\text{.}\) On définit les moments:
avec \(\gamma\) et \(\beta\) des paramètres entraînables et \(\hat{x}_i=\frac{x_i-\sigma^2_{\mathcal{B}}}{\sqrt{\sigma^2_{\mathcal{B}}+\epsilon}}\text{.}\)
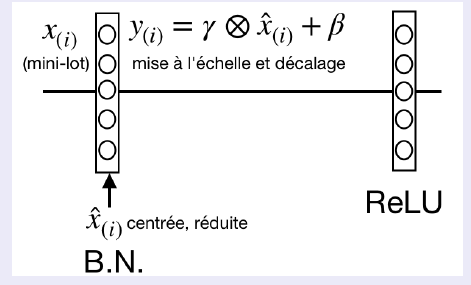
On voit qu'on centre réduit les données avant de réapprendre le décalage et la mise à l'échelle optimaux. Le processus est détaillé sur l'image (((xref without ref, first/last, or provisional attribute (check spelling)))).
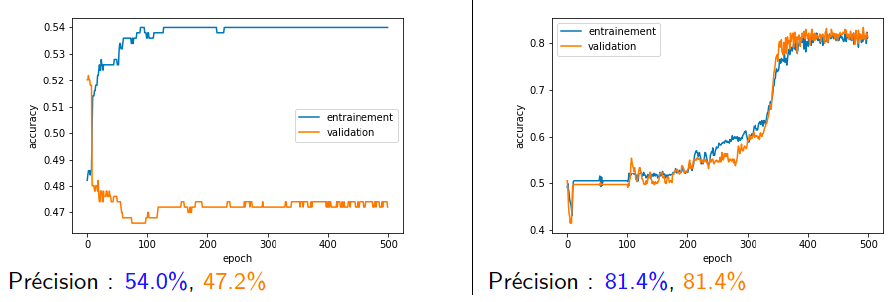
Figure5.17.Principe de la normalisation par batch. Sur la figure Figure 5.18 on voit qu'un réseau a vingt couches est instable sans normalisation par mini-lot, mais devient stable avec et cela permet d'effectuer un apprentissage valide.
Figure5.18.Résultats d'apprentissage sur un réseau profond avant et sans normalisation par mini-lôt. Les instabilités de gradients sont un problème classique en apprentissage profond, mais ce problème peut être limité par un certain nombre de méthodes que nous avons introduit ici. On en verra d'autres notamment pour les réseaux convolutifs que l'ont va introduire.
Subsection5.1.4Biais Spectral
Le biais spectral est un principe qui décrit le comportement pendant l'apprentissage des réseaux en regime sur-paramétré. Le régime sur-paramétré correspond au cas le nombre de paramètres du réseaux largement supérieur aux nombres de données. Parfois on l'approche par la limite \((n_1,...n_L) \rightarrow +\infty\) avec \(n_i\) le nombre de neurones de la couche \(i\) de notre réseau.
Biais spectral.
Soit une fonction \(f\) que l'ont cherche a approcher par un réseau \(f_{\theta}\text{.}\) Pour les réseaux de type MPC en régime sur-paramétré, les basses fréquences de la fonction \(f\) sont apprisent plus rapidement que les hautes fréquences.
Ce principe nous montre que les réseaux ont tendance a générer des fonctions très plates très basse fréquence en première approximation avant de progressivement monter en fréquence. Cela permet d'avoir des bonnes capcacités de généralisation. On va montrer se principe numériquement a travers des exemples et une comparaison avec une régression polynomial.
Figure5.19.Résultats donnés par une régression polynomial de degrés 800 lors d'une méthode de gradient. 120 données. Premières époques en haut et dernière en bas (20000). On voit sur la figure Figure 5.19 que le modèle polynomial s'améliore lentement. Cependant dans ce regime sur-paramètré le modèle polynomial a tendance a toujours osciller. Cela compromet ses capacités de généralisation.
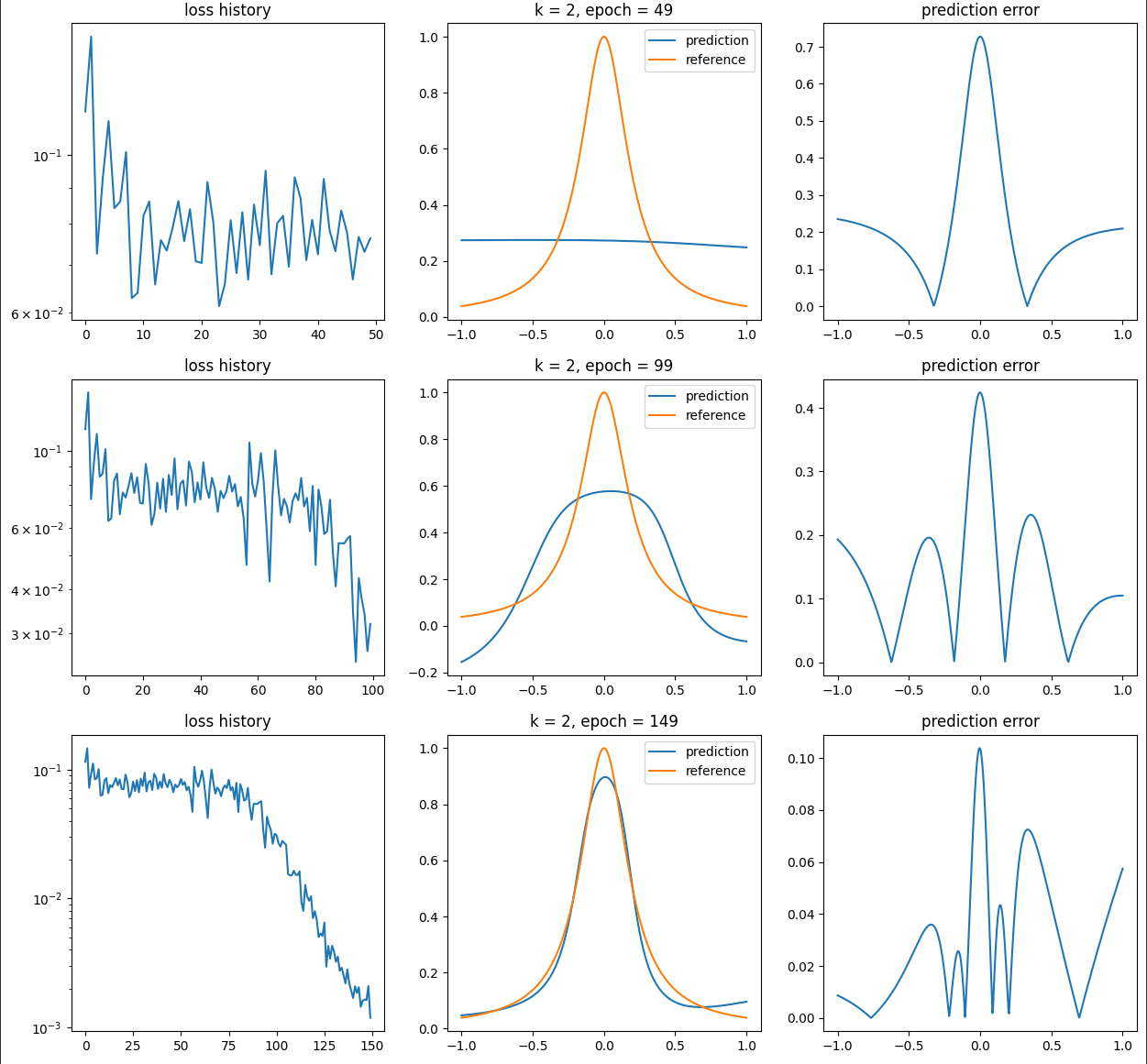
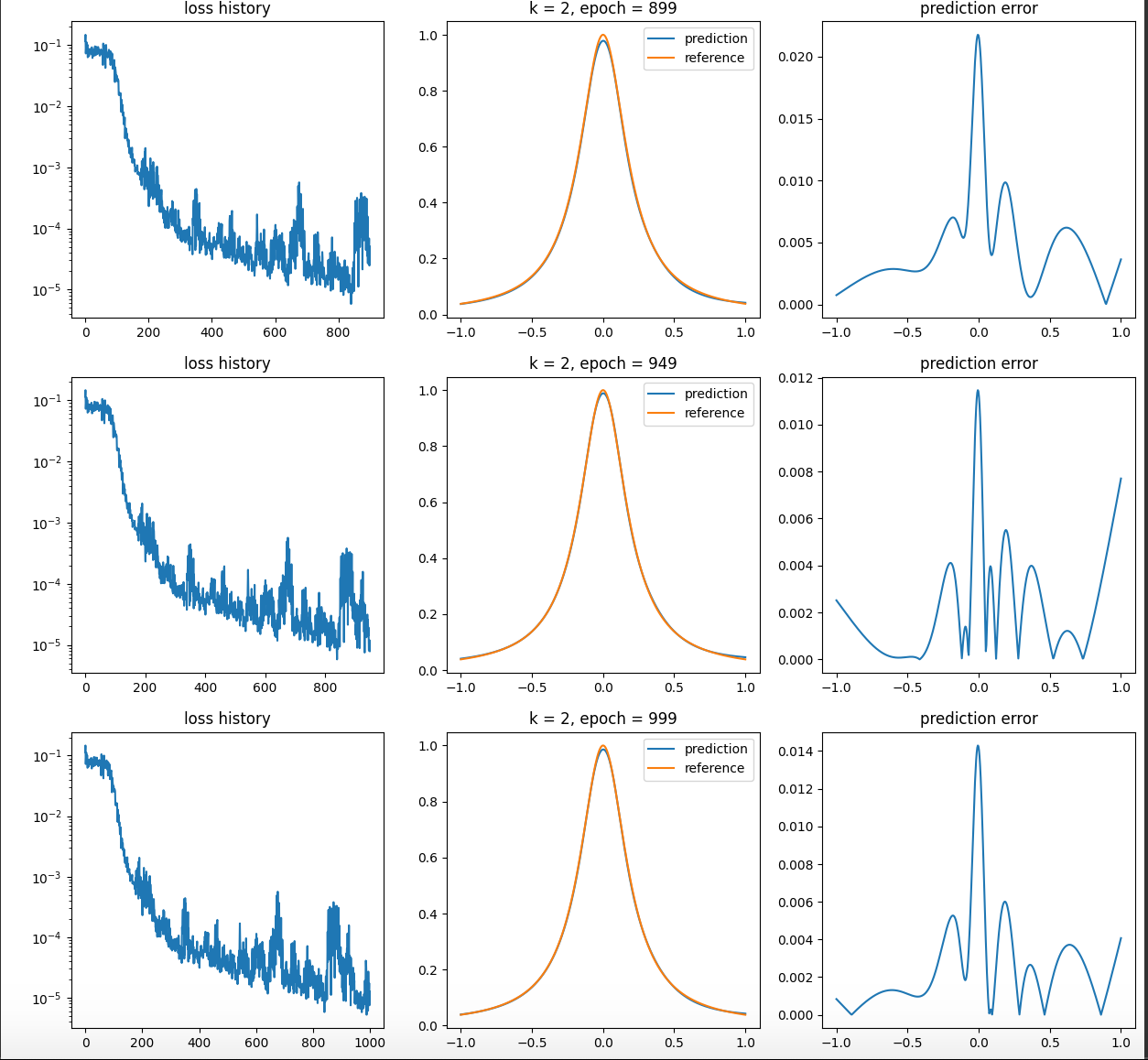
Figure5.20.Résultats donnés par une régression avec un réseau de neurones à environ 800 paramètres lors d'une méthode de gradient. 120 données. Premières époques en haut et dernière en bas (1000). A l'inverse sur la figure Figure 5.20, on remarque que le réseau arrive très bien a converger et pour cela il va commencer par une approximation très plate avant de progréssivement converger vers la solution sans osciller. Il s'agit d'une illustration du biais spectral et qui peut expliquer le succès des réseaux qui globalement connaisse moins de problème de sur-apprentissage grace entre autre a ce principe.
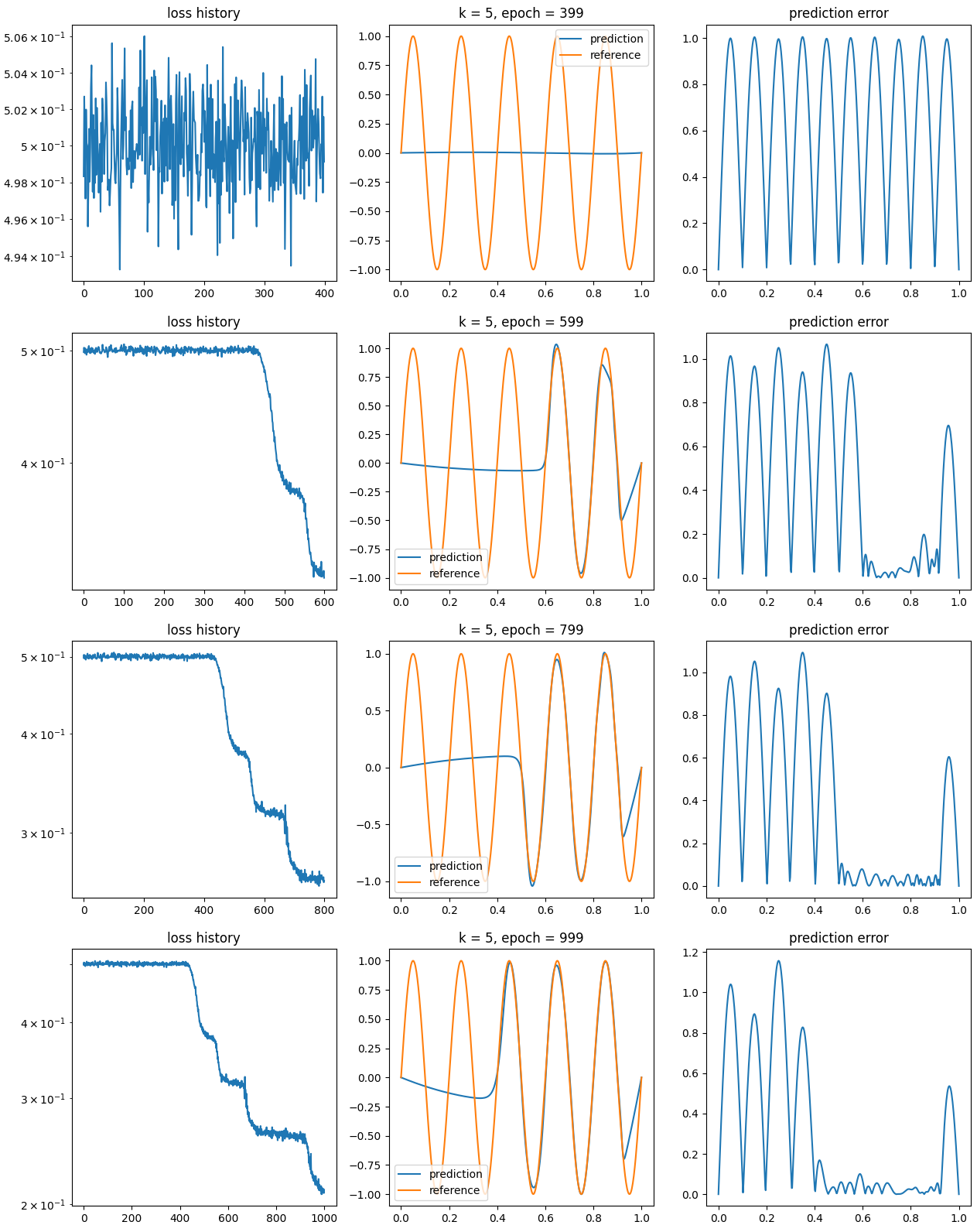
Figure5.21.Résultats donnés par une régression avec un réseau de neurones en régime sur-paramétré sur un sinus oscillant. Sur la figure Figure 5.21 on donne un autre exemple de ce principe. On voit la encore qu'on part d'une approximation très plate. Puis progressivement on apprend les oscillation de droite a gauche (cela peut être de gauche a droite) en restant très basse fréquence dans les zones par encore apprises.