Section 3.2 Rappel sur la régression et le maximum de vraisemblance
Ici on va rappeler la notion de régression linéaire qui permet de construire un modèle linéaire approchant au mieux des données. Il s'agit de premier modèle de régression. Pour construire ces modèles, on va se placer dans le cadre probabiliste qui est plus général.
Il s'agit d'une méthode développée par le statisticien Fisher en 1922. Elle permet la construction d'un estimateur statistique permettant de calculer une loi inférant les paramètres d'une loi inconnue dont on connaît un échantillon. Il s'agit d'une méthode générique basée sur la maximisation d'une fonction appelée fonction de vraisemblance. La fonction de vraisemblance quantifie la probabilité qu'un échantillon soit issu d'une loi donnée. Étant donné un échantillon observé \((x_1,\ldots,x_n)\) avec \(x \in \mathbb{R}^d\) et une loi de probabilité \(\mu_{\theta}\text{,}\) la fonction de vraisemblance quantifie la probabilité que les observations proviennent effectivement d'un échantillon (théorique) de la loi \(\mu_{\theta}\text{.}\)
Subsection 3.2.1 Estimateur de maximum de vraisemblance
Se donnant une loi paramétrique, on va chercher à maximiser la fonction de vraisemblance afin de trouver la loi qui maximise le fait que l'échantillon puisse être expliqué par elle. Pour mieux comprendre la définition qui suit, considérons un \(n\)-échantillon \((X_1,\dots ,X_n)\) de loi \(\mu_{\theta}\) discrète donnée par la probabilité \({P}_{\theta}\text{.}\) Soit \((x_1,\dots,x_n)\text{,}\) une observation de cet échantillon. On montre aisément que
en utilisant que les variables \((X_i)_{1\leq i\leq n}\) sont indépendantes. La méthode du maximum de vraisemblance revient à considérer qu'il est raisonnable d'estimer le paramètre \(\theta\) comme celui maximisant la probabilité de réalisation de \((x_1,\dots,x_n)\) définie ci-dessus.
Dans le cas où la loi \(\mu_{\theta}\) est donnée par une densité continue \(f_\theta\text{,}\) on se donne \(\varepsilon>0\) et on cherche à estimer \(\mathbb{P}\left(\bigcap_{i=1}^n\{|X_i-x_i|\leq \varepsilon\}\right)\text{.}\) On a
Notons que \(\int_{x_i-\varepsilon}^{x_i+\varepsilon}f_\theta(x)\, dx\sim 2\varepsilon f_\theta(x_i)\) lorsque \(\varepsilon \to 0\) et par conséquent,
Pour s'extraire de la dépendance en \(\varepsilon\text{,}\) on considère qu'il est raisonnable de chercher à maximiser \(\lim_{\varepsilon\to 0}\mathbb{P}\left(\bigcap_{i=1}^n\{|X_i-x_i|\leq \varepsilon\}\right)/(2\varepsilon)^n\text{.}\)
Définition 3.6. Fonction de vraisemblance.
Soit \(X\text{,}\) une v.a.r. discrète ou à densité sur l'espace probabilisé \((\Omega,\mathcal{A},\mathbb{P})\) de loi \(\mu_{\theta}\) définie par la probabilité \({P}_{\theta}\) dans le cas discret et par une densité \(f_{\theta}\) sinon, dont on veut estimer le paramètre \(\theta\) appartenant à un ensemble \(\Theta\text{.}\)
Soit
Soit \((x_1,\dots ,x_n)\text{,}\) un \(n\)-échantillon de loi \(\mu_{\theta}\text{.}\) La fonction de vraisemblance \(\mathcal{L}\) associée à cet échantillon est définie par
Maintenant que la fonction est introduite on obtient l'estimateur par maximisation. En général on résout problème reformulé, qu'on appelle maximum du log vraisemblance. Il s'agit simplement de prendre le log de la fonction de vraisemblance ce qui permet d'obtenir une somme au lieu d'un produit ce qui est plus facile a dérivée.
Définition 3.7. Estimateur de maximum de vraisemblance/de log vraisemblance.
Lorsque la fonction de vraisemblance admet un unique maximum, l'estimateur du maximum de vraisemblance \(\hat{\theta}_n\) est défini par
On définit également l'estimateur du maximum de log vraisemblance \(\hat{\theta}_n\) par
On va maintenant donner un rapide exemple.
Exemple 3.8.
On considère un échantillon \((x_1,\dots,x_n)\in \{0,1\}^n\) tiré selon une loi binomiale \(\mathcal{B}(1,p)\text{,}\) et on cherche à estimer \(\theta=p\in [0,1]\text{.}\) Remarquons que \(\sum_i x_i\) représente la quantité totale de "1" obtenue dans l'échantillon. Estimons \(p\text{.}\)
La fonction de vraisemblance s'écrit alors :
en utilisant que \(\mathbb{P}_\theta(\{X_i=1\})=p=\theta\) et \(\mathbb{P}_\theta(\{X_i=0\})=1-p=1-\theta\text{.}\)
Remarquons que les extrémités de l'intervalle \([0,1]\) ne peuvent pas résoudre le problème de maximisation
sauf si \(\sum_ix_i\in \{0,n\}\text{.}\) Par ailleurs, il est aisé de se convaincre que ce problème possède une unique solution dans \([0,1]\text{.}\) On en déduit que la solution \(\theta^*\) est donnée par
Ainsi, on retrouve l'estimateur de l'espérance obtenu en appliquant la loi des grands nombres, ce qui est cohérent puisque \(p=\mathbb{E}(X_i)\text{.}\)
On va rapidement introduire des résultats de convergence pour la méthode. l'objectif est notamment de quantifier la précision de l'estimateur de maximum de vraisemblance. Dans la suite on considérera que la fonction de fr log vraisemblance est de régularité suffisante.
Proposition 3.9.
Soit \(X\) une variable aléatoire. On nomme le score la dérivée de la fonction de log vraisemblance
Ce score est d'espérance:
Preuve.
Définition 3.10.
On nomme l'information de Fisher comme le moment d'ordre 2 de la fonction de log vraisemblanceProposition 3.11.
L'information de Fisher peut se réécrire sous la forme
Preuve.
L'information de Fisher qui mesure la courbure va permettre d'obtenir des résultats sur les estimateurs et plus particulièrement celui du maximum de vraisemblance.
Théorème 3.12. Borne de Cramer-Rao.
Soit \((x_1,....x_n)\) un échantillon d'une variable aléatoire \(X\) de loi \(f(x,\theta)\) ( ou \(\mathbb{P}_{\theta}\) dans le cas discret). Soit \(\hat{\theta}_n\) un estimateur sans biais de \(\theta\text{.}\) On peut donner une borne inférieure de la variance:
Théorème 3.13. Théorème de convergence.
Soit \((x_1,....x_n)\) un échantillon d'une variable aléatoire \(X\) de loi \(f(x,\theta)\) ( ou \(\mathbb{P}_{\theta}\) dans le cas discret). Soit \(\hat{\theta}_n\) un estimateur du maximum de vraisemblance. Lorsque \(n\rightarrow \infty\) on a la convergence en loi
Subsubsection 3.2.1.1 Limite asymptotique de l'estimateur du maximum de vraisemblance
Pour finir cette section, on va montrer que dans la limite \(n\) grand, résoudre le problème du maximum de vraisemblance revient a minimiser une certaine "distance" entre la distribution générée par le paramètre \(\hat{\theta}_{\infty}\) et la distribution cible. Pour cela on va d'abord introduire une notion de distance.
Définition 3.14. Divergence de Kullback-Leibler.
Soit \(P\) et \(>Q\) deux distributions de probabilité. La divergence de Kullback Leibler est définie parDans le cas discret par:
\begin{equation*} D_{KL}(P\mid\mid Q)=\sum_{i=1}P(i)\operatorname{log}\left(\frac{P(i)}{Q(i)}\right) \end{equation*}Dans le cas continu par:
\begin{equation*} D_{KL}(P\mid\mid Q)=\int_{-\infty}^{\infty}p(x)\operatorname{log}\left(\frac{p(x)}{q(x)}\right)dx \end{equation*}
On appelle la divergence KL aussi l'entropie relative entre les deux distributions.
Proposition 3.15.
La divergence de Kullback-Leibler satisfait les propriétés suivantes:
\(\displaystyle D_{KL}(P\mid\mid Q) \geq 0\)
\(D_{KL}(P\mid\mid Q) =0\) implique \(P=Q\) presque surement.
La divergence KL n'est pas une distance au sens de la théorie des espaces métriques, car elle est non symétrique.
Théorème 3.16.
Soit \(\mathcal{X}=(x_1,...x_n)\) un échantillon issu de variables aléatoires de loi \(p_{\theta_{ref}}(x)\text{.}\) Soit \(\hat{\theta}\) l'estimateur du maximum de vraisemblance. Lorsque \(n\rightarrow \infty\) est solution du problème de minimisation
Preuve.
Il s'agira une preuve très formelle, notamment sur le passage à la limite.
On considère l'estimateur du maximum de vraisemblance. Soit:
avec \(g_{\theta}(x)=log \left(\frac{f_{\theta_{ref}}(x)}{f_{\theta}(x)}\right)\text{.}\) On utilise ici le passage à la limite entre l'espérance empirique d'une fonction de variable aléatoire. On obtient donc en passant à la limite que
Ensuite, puisque \(x\) est distribué selon \(f_{\theta_ref}\) on a
ce qui donne par définition
ce la revient à
Subsection 3.2.2 Régression linéaire probabiliste
On va maintenant introduire le problème de de régression. L'enjeu est de construire un modèle qualitatif à partir de données.
Définition 3.17. Problème de régression probabiliste.
On se donne un jeu de données \(\mathcal{X}=(x_1,....,x_n) \in \mathbb{R}^d\) et \(\mathcal{Y}=(y_1,....,y_n) \in \mathbb{R}\) des échantillons i.d.d de deux variables aléatoires continues \(X\) et \(Y\text{.}\) On suppose qu'il existe une loi de probabilité \(\mathbb{P}(Y\mid X)\text{.}\) La régression consiste a construire une loi paramètrique \(\mathbb{P}_{\theta}(Y\mid X)\) approchant (en un certain sens) \(\mathbb{P}(Y\mid X)\text{.}\)
On va introduire un premier modèle de loi de probabilité paramétrée \(\mathbb{P}_{\theta}(Y\mid X)\) le plus simple qu'on puisse imaginer et montrer comment le construire.
Définition 3.18. Modèle linéaire.
Le modèle linéaire consiste à se donner une loi de probabilité paramétrée pour le problème de régression Définition 3.17 de la forme:
avec les paramètres \(\omega\in \mathbb{R}^d\text{,}\) \(b\in \mathbb{R}\) et \(\mathcal{N}\) une loi Gaussienne. \(\sigma \in \mathbb{R}\) est fixé et modélise l'incertitude sur les données.
Maintenant la question est de savoir comment construire le modèle \(p_{\theta}(y \mid x)\) à partir d'échantillon. La fonction de vraisemblance mesure a quel un point un échantillon vérifie une loi de probabilité. On voit donc qu'on veut donc construire les paramètres du modèle \(\theta=(\omega,b)\in \mathbb{R}^{d+1}\) de façon a maximiser la vraisemblance sur l'échantillon. On va donc construire le modèle avec l'estimateur du maximum de vraisemblance.
Proposition 3.19. Modèle linéaire par maximum de vraisemblance.
Les paramètres \(\theta=(\omega,b)\) du modèle de régression linéaire probabiliste (3.7) construit par maximum de vraisemblance sont solution du problème de moindre carré:
avec \(A_x \in \mathcal{M}_{n,d+1}(\mathbb{R})\) et \(b_y \in \mathcal{M}_{n,1}(\mathbb{R})\) par
Si \(n > d+1\) il existe une unique solution grace aux lemmes Lemme 3.2 et Lemme 3.3. Pour un nouveau point \(x\) la prédiction est donné par
Preuve.
Afin de déterminer les paramètres \(\theta=(\omega,b)\) On va donc calculer l'estimateur du maximum de vraisemblance (3.4) pour le modèle linéaire (3.7). On introduit la vraisemblance associée:
Pour maximiser cette fonction on va devoir calculer les dérivées. Pour simplifier le calcul, on propose de transformer les produits en somme en appliquant une fonction "log". Cette fonction étant croissante maximiser le log de la vraisemblance maximise aussi la vraisemblance.
En appliquant la fonction log, on obtient
En utilisant le caractère Gaussien de notre loi paramétrée on obtient
Maximiser la fonction (3.11) revient à minimiser la fonction
puisque les autres termes de (3.11) ne dépendent pas de \(\omega\) et \(b\text{.}\) On voit donc maximiser la log vraisemblance ici revient a minimiser l'erreur au sens des moindres carrés et donc résoudre un problème du type (3.1).
Proposition 3.20.
Soit \(\mathcal{X}\) avec \(d=1\) et \(\mathcal{Y}\) les échantillons. La solution du problème de régression linéaire au sens des moindres carrés (3.8) et (3.9) est donné par
avec \(\bar{x}\text{,}\) \(\bar{y}\) les moyennes empiriques des échantillons.
Preuve.
Dans ce cas particulier
un rapide calcul matriciel montre que
et
Maintenant on inverse la matrice en utilisant la formule d'inversion d'une matrice \(2x2\text{.}\) Cette matrice est inversible si sont déterminant est donc nul, donc ici si
et l'inverse est donnée par
On remarque que
On applique la même formule pour \(\frac{1}{n}\sum_{i=1}^nx_i^2-\bar{x}^2\) et cela nous donne en calculant le produit matrice vecteur que
Pour \(b\) on obtient
donc
Le maximum de vraisemblance nous permet donc de donner un cadre à la construction de modèle paramétré inférant des données. On a vu que cela se ramenait a un problème de moindre carré que l'ont peut résoudre par la méthode de l'équation normale. Le cadre déterministe est contenu dans le cadre probabiliste et se récupère avec \(\sigma \lt \lt 1\text{.}\)
Subsubsection 3.2.2.1 Formulation duale de la régression
On repart de notre problème de régression (3.8) - (3.9). Comme ont le sait la solution est donné par l'équation normale
Supposons maintenant que notre matrice \(A^t A\) soit inversible. On peut donc écrire
avec \(\theta=A(A^t A)^{-2}A^t b\text{.}\) On voit donc qu'on peut toujours écrire le résultat de la régression sous la forme d'une combinaison linéaire des points d'échantillonnages:
avec
On rappelle que par définition de la régression linéaire on cherche une fonction \(f(x)=\langle \theta,x\rangle\text{.}\) En utilisant (3.13) et cette définition on obtiendra la prédiction du modèle à partir de \(\alpha\text{.}\) Cette formulation inverse une matrice carrée de taille \(n\) la ou la formulation primale inversait une matrice de taille \(d+1\text{.}\) Elle peut donc être intéressante en grande dimension.
Proposition 3.21. Formulation duale de la régression.
Les paramètres \(\theta=(\omega,b)\) du modèle de régression linéaire probabiliste (3.8) avec \(A_x \in \mathcal{M}_{n,d+1}(\mathbb{R})\) et \(b_y \in \mathcal{M}_{n,1}(\mathbb{R})\) par (3.9) sont solution de
avec \(\tilde{x}_i= (x, 1)^t\) et \(\alpha\) solution de
ou \(K\in \mathcal{M}_{n,n}\) est une matrice définie par \(K_{ij}=\langle \tilde{x}_i,\tilde{x}_j\rangle_{\mathbb{R}^{d+1}}\text{.}\)
Pour un nouveau point \(\tilde{x}=(x,1)^t\) la prédiction est donnée p
La matrice \(K\) est une matrice de Gram. Il s'agit des matrices générées par des produits scalaires de données. Ce type matrice matrice est symétrique positive par construction. Elle est inversible si les vecteurs \((\tilde{x}_1,...,\tilde{x}_n)\) forme une famille libre. On voit que cette formulation duale utilise au maximum le produit scalaire dans \(\mathbb{R}^n\text{.}\) Les produits Cette formulation nous sera utile par la suite.
Subsection 3.2.3 Régression polynomiale
Le 1er choix pour traiter les problèmes non linéaires est d'utiliser une approximation polynomiale. En effet le théorème de Stone-Weierstrass nous dit que toute fonction continue définie sur un segment de \(\mathbb{R}\) peut être uniformément approchée par des polynômes. De la même façon les polynômes orthogonaux forment une base de l'espace des fonctions \(L^2\) ce qui assure une approximation des fonctions \(L^2\) par une suite de polynômes. On va introduire la méthode pour \(d=1\text{.}\)
Définition 3.22. Modèle Polynomial.
Le modèle polynomial consiste à se donner une loi de probabilité paramétrée pour le problème de régression Définition 3.17 de la forme:
avec \(p_i(x)\) des polynômes, les paramètres \(\theta\in \mathbb{R}^{k}\) et \(\mathcal{N}\) une loi Gaussienne. \(\sigma \in \mathbb{R}\) est fixé et modélise l'incertitude sur les données.
On décide donc d'approcher la moyenne dans notre modèle par une somme de polynômes. On peut prendre une base de polynômes de degré croissant ou des polynômes de Lagrange.
Comme dans le cas linéaire, on peut montrer qu'appliquer une méthode de maximum de vraisemblance permet de se ramener un problème aux moindres carrés avec une matrice:
Puisqu'on se ramène un problème aux moindres carrés, on peut le résoudre avec l'équation normale ou une autre méthode. La méthode peut s'étendre en dimension \(d>1\text{,}\) mais le nombre de coefficients explose avec la dimension. Si on prend la base canonique des polynômes, on se donne un degré maximal \(q\) par direction. Dans ce cas on va avoir \(n_c=(q+1)^d\) coefficients. Pour \(q=5\) et \(d=10\) on a déjà autour de 60 millions de coefficients. Ce type de régression est rarement utilisée en grande dimension.
Subsection 3.2.4 Classification
La régression logistique est une méthode (il y a en a beaucoup d'autres) pour résoudre le problème de classification (catégorisation) de données .
On part d'un jeux de données de \(\mathcal{X}=\left\{x_1,..x_n\right\}\) avec \(x\in \mathbb{R}^d\text{.}\) On suppose que ses données appartiennent à des classes ou catégories. On parle de classification supervisée binaire s’ il y a deux catégories. Exemple:
\(y\) correspond a une image qui est soit un chat \((y=1)\) soit non \((y=0)\)
\(y\) correspond a une radio qui indique soit une tumeur \((y=1)\) soit non \((y=0)\)
Dans le cas avec \(n_c\) catégories on obtient donc que les données cibles \(y\) appartiennent à l'ensemble discret \(\left\{1,2,...,n_c\right\}\text{.}\)
Subsubsection 3.2.4.1 Régression logistique
On se place dans le cadre \(n_c=2\text{.}\) La variable \(y\) peut donc prendre deux valeurs \(y \in \left\{0,1\right\}\text{.}\) Au nuage de points \(\mathcal{X}\) on associe un ensemble de labels \(\mathcal{Y}=(y_1,..y_n)\text{.}\) La classification supervisée revient à construire la loi conditionnelle de \(y\) sachant \(x\) sous la d'une loi de Bernoulli:
Définition 3.23. Classification supervisée.
On remarque que:
\(\operatorname{lim} f(x)\rightarrow -\infty\) implique que \(\mathbb{P}(y=1 \mid x)\rightarrow 0\) donc \(y = 0\text{,}\)
\(\operatorname{lim} f(x)\rightarrow \infty\) implique que \(\mathbb{P}(y=1 \mid x)\rightarrow 1\) donc \(y = 1\text{,}\)
\(\operatorname{lim} f(x)\rightarrow 0\) implique que \(\mathbb{P}(y=1 \mid x)\rightarrow 0.5\) et dans ce cas il y a indécision.
Cela nous permet de définir le modèle \(logistique\text{.}\) Pour un problème de classification binaire, le >modèle logistique consiste à approcher les probabilités conditionnelles par
Définition 3.24. Modèle logistique.
Maintenant que le modèle est introduit, on doit mettre en place la stratégie d'apprentissage. Pour cela on doit d'abord construire une fonction coût. On doit faire coller le modèle aux données. Pour cela un outil naturel est l'estimateur du maximum de vraisemblance qui permet d'ajuster un modèle à partir des données. On rappelle la vraisemblance de notre problème:
En utilisant les propriétés de la loi de Bernoulli, cette vraisemblance peut se réécrire:
En général on ne souhaite pas maximiser la vraisemblance à cause du produit de probabilité, on préfère maximiser le log de cette vraisemblance. On prend donc le log:
En général on préfère un problème a minimiser. Pour un problème de classification binaire, on utilise une fonction coût appelée entropie croisée: On appelle la régression logistique la méthode qui utilise le modèle logistique (3.16) en minimiser la fonction de coût entropie croisée binaire (3.17). Le gradient de la fonction de coût entropie croisée (3.17) appliquée au modèle (3.16) est donné par: et
Définition 3.25. Fonction coût entropie croisée binaire.
Définition 3.26. Régression logistique.
Proposition 3.27.
Preuve.
On commence par réécrire la fonction coût:
Maintenant on calcul le gradient avec des formules de dérivées composées et on obtient le résultat.
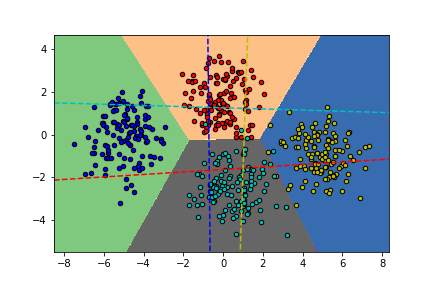
Subsubsection 3.2.4.2 Régression logistique polytomique
On cherche maintenant a étudier le cas \(n_c>2\text{.}\) La variable \(y\) peut donc prendre deux valeurs \(y \in \left\{0,n_c\right\}\text{.}\) Au nuage de points \(\mathcal{X}\) on associe un ensemble de label \(\mathcal{Y}=(y_1,..y_n)\text{.}\) De la même façon que précédemment on cherche a construire des probabilités conditionnelles qui prennent cette fois-ci la forme:
Ici on va construire un modèle de régression capable de traiter directement le cas multi classe. La méthode de la régression logistique partait d'un modèle dit logistique qui prenait une transformation affine des données avant de les transformer en probabilité à l'aide de la fonction sigmoïde. Ici on va faire la même chose, mais on doit générer une loi de probabilité prenant possiblement \(n_c\) valeur et non deux. On ne donc donc pas construire un seuil \(p\text{,}\) mais \(n_c-1\) seuils donc \(n_c\) probabilités qui seront approchées de façon affine. Pour un problème de classification polytomique, le modèle consiste à approcher les probabilités conditionnelles par On voit que toutes les probabilités sont positives et leurs sommes fait \(1\text{.}\) On a donc une loi de probabilité discrète.
Définition 3.28. Modèle Softmax.
On voit qu'on peut réécrire cette vraisemblance à l'aide de fonction indicatrice:
De façon similaire au cas binaire, on souhaite (pour le calcul du gradient de la vraisemblance) utiliser le logarithme afin de passer de produit à des sommes. On prend donc le log:
En général on préfère un problème a minimiser. Pour un problème de classification polytomique, on utilise une fonction coût appelée entropie croisée: On appelle la régression logistique la méthode qui utilise le modèle logistique (3.18) en minimiser la fonction de coût entropie croisée binaire (3.19).
Définition 3.29. Fonction coût entropie croisée.
Définition 3.30. Régression logistique polytomique.
avec \(\operatorname{softmax}\) uen fonction vectorielle de taille \(n_c\) dont la ligne \(k\) vaut \(\displaystyle \frac{e^{\langle\omega_k,x\rangle+b_k}}{\sum_{l=1}^{n_c}e^{\langle\omega_l,x\rangle+b_l}}\text{.}\) 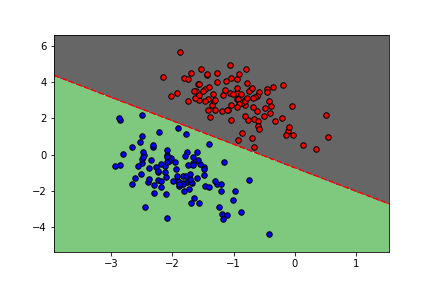
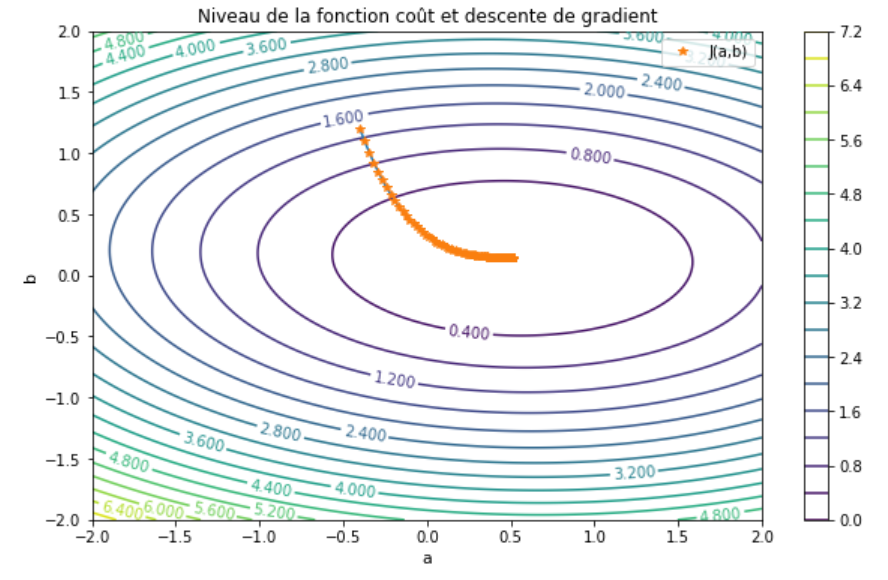
Subsection 3.2.5 Méthodes de gradient
Pour résoudre notre problème de régression pon peut résoudre l'équation normale Lemme 3.3. En grande dimension la matrice a inverser peut devenir grande et donc le processus peut devenir coûteux. Une autre solution est de résoudre le problème du type (3.1) avec des méthodes de gradients. Ces méthodes seront centrales pour des modèles plus compliqués qu'on abordera par la suite.
Subsubsection 3.2.5.1 Méthode de gradient classique
On va commencer par réintroduire l'approche classique de descente de gradient. Dans le cadre des méthodes d'apprentissage introduites précédemment on cherche a minimiser avec
Le premier algorithme est appelé l'algorithme de gradient à pas fixe. On souhait donc résoudre
Cela peut se réécrire:
avec \(\eta \gt 0\text{.}\) En posant \(g(.)=I_d-\eta\nabla_{\theta} \mathcal{J}(.)\) on voit qu'on se ramène a un problème de point fixe. Cela nous donne donc un algorithme immédiat.
Algorithm 3.32. Algorithme de descente de gradient à pas fixe.
On initialise \(\theta_0\)
-
Tant que \(\parallel \nabla_{\theta} \mathcal{J}(\theta_k)\parallel \gt \epsilon\)
on calcul \(d_k=\mathcal{J}(\theta_k)\)
-
On fait la mise à jour
\begin{equation*} \theta_{k+1}=\theta_k-\eta d_k \end{equation*} On renvoie \(\theta_K\text{.}\)
On peut montrer assez facilement que sous des conditions assez restrictives cette méthode converge.
Définition 3.33. Convexité forte.
On dit qu'une fonction \(\mathcal{J}\text{,}\) définie sur un ensemble convexe \(K\text{,}\) est \(\alpha\)-convexe s'il existe \(a>0\) tel que, pour tout \(u, v \in K\) et tout \(t \in[0,1]\text{,}\)
Cette condition revient a demander à une fonction d'être convexe aux moins aussi fortement qu'une fonction quadratique.
Proposition 3.34.
Soit \(\mathcal{J}\) une application différentiable de \(K\) dans \(\mathbb{R}\) et \(\alpha>0\text{.}\) Les assertions suivantes sont équivalentes \(\mathcal{J}\) est \(\alpha\)-convexe sur \(K\text{,}\)
Maintenant, on donne le résultat de convergence de la méthode de gradient.
Théorème 3.35.
On suppose que \(\mathcal{J}\) est \(\alpha\) conxeve et différentiable et que \(\nabla_{\theta} \mathcal{J}(\theta)\) est Lipschitzien sur \(K\text{,}\) c'est-à-dire qu'il existe une constante \(L>0\) telle que
Alors, si \(0\lt \eta \lt 2 \frac{\alpha}{L^2}\text{,}\) l'algorithme de gradient à pas fixe converge: quel que soit \(\theta_0\text{,}\) la suite \(\left(\theta_{k}\right)\) converve vers la solution \(\theta^*\) de (3.20).
Preuve.
On commence par définir \(g(\theta)=\theta-\eta\nabla_{\theta} \mathcal{J}(\theta)\text{.}\) On va donc calculer
Maintenant on va utiliser la \(\alpha\)-convexité et plus précisément la proposition Proposition 3.34 qui nous permet de majorer le terme. Le troisième terme est majoré en utilisant le côté Lipschitzien du gradient. Cela permet d'obtenir:
et on conclue en remarquant que si \(0\lt \eta \lt 2 \frac{\alpha}{L^2}\) alors \(\left(1-2\alpha\eta +L^2\eta^2\right)\lt 1\) l'application \(g\) est contractante et donc par le théorème de point on a convergence vers
ce qui est équivalent à \(\nabla_{\theta} \mathcal{J}(\theta^*)\text{.}\)
Il existe un certain nombre de variantes de la méthode. On peut citer le gradient à pas optimal qui calcul un pas \(\alpha\) de façon assurer la descente de gradient. On peut aussi citer le gradient conjugué qui prend comme direction de descente une moyenne du gradient et la direction de descente précédente.
Nous avons construit la méthode de descente de gradient par un argument de point fixe. On peut aussi utiliser une autre construction, basée sur les EDO, qui est parfois utilisée pour analyser les méthodes d'optimisation pour l'apprentissage. On pose l'équation:
Ce type d'EDO est appelé un un flot de gradient. On écrit donc la dynamique des poids de notre modèle d'apprentissage comme une dynamique en temps. L En multipliant cette équation par \(\nabla_{\theta} f(\theta(t))\) on obtient que
ce qui montre bien que \(f(\theta(t))\) (qui correspond à l'erreur de notre modèle) diminue en temps. Les états stationnaires du système sont caractérisés par \(\frac{d \theta(t)}{dt}\) et donc \(\nabla_{\theta} f(\theta(t))\text{.}\) On voit donc résoudre notre problème de minimisation revient a chercher un état stationnaire de notre EDO. Si on discrétise cette EDO avec un schéma d'Euler on obtient
On voit donc que la méthode de descente de gradient s'écrit comme un schéma d'Euler pour un flot de gradients avec \(\alpha=\Delta t \text{.}\) Sous cette forme l'EDO (3.21) peut modéliser la trajectoire d'un point le long d'un potentiel (ou d'une bille le long d'un "paysage"). La fonction \(f(\theta(t))\) est une fonction de Lyapunov du système.
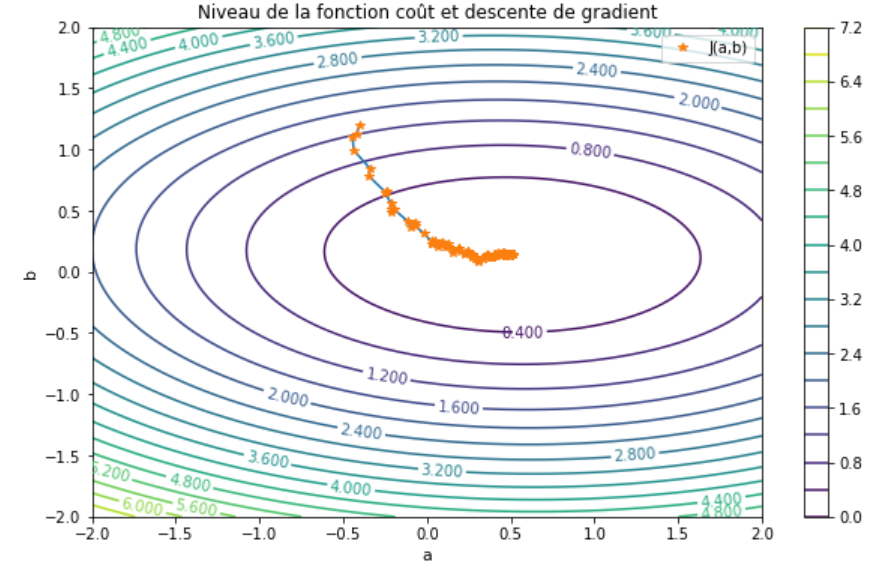
Subsubsection 3.2.5.2 Méthode de gradient stochastique
La méthode de gradient stochastique est une variante de la méthode de gradient qui est absolument central pour les problèmes d'apprentissage. Pour ce genre de problème on peut souvent écrire la fonction a minimiser sous la forme d'une somme de fonction de coût:
Par exemple dans le cas d'une régression on a \(j_i(\theta)=l(f_{\theta}(x_i),y_i)\text{.}\) Si on applique la méthode de gradient classique avec un pas variable donné, on obtient l'algorithme:
On voit donc que le calcul du gradient faire intervenir l'ensemble des loss j_i. En apprentissage \(N\) représente le nombre de données qui peut être grand. Le calcul du chaque gradient associé à l'erreur commise par le modèle pour chaque donnée peut donc devenir très lourd. Afin de limiter cela il a été proposé une alternative appelée gradient stochastique. L'idée est d'utiliser l'itéré suivant:
avec \(i^r\) tiré aléatoirement dans \(\left\{1,...,N\right\}\text{.}\) On utilise donc le gradient sur une seule donnée à chaque itération. Évidemment il n’est pas immédiat que cette approche converge. On va montrer par la suite que si.
Proposition 3.36.
On suppose que \(\mathcal{J}(\theta)\) est \(\alpha\)-convexe, admet un unique minimum, et qu'il existe une constante \(C\text{,}\) indépendante de \(N\text{,}\) telle que pour tout \(\theta \in \mathbb{R}^{n_{\theta}}\) alors
où \(\theta^*\) désigne l'unique point de minimum de \(\mathcal{J}(\theta)\text{.}\) Si la suite des pas vérifie \(\eta_k=\frac{1}{k+1},\) alors l'algorithme du gradient stochastique (3.23) converge (en moyenne).
Preuve.
La preuve est issue du cours [1.19]. On commence par réécrire (3.23)
dont on calcule la norme au carré
On définit une loi uniforme discrète \(p_u\) qui tire au sort aléatoirement l'indice \(i_k\) parmi \(\left\{1,...,N\right\}\text{.}\) On remarque que l'espérance selon \(p_u\) est donnée
On peut calculer l'espérence du carré de la même façon
On va maintenant prendre l'espérance de l'égalité (3.25) et en utilisant les deux identités introduites juste au dessus. On obtient:
Maintenant on utilise la \(\alpha\) convexité de la fonction \(\mathcal{J}\text{,}\) on obtient:
Pour finir on utilise l'hypothèse (3.24) on obtient:
On pose le coefficient d'amplification
qui est plus petit que strictement inférieur à un sous la condition sur \(\eta_k\) introduite dans la proposition. Par récurrence on a:
avec \(c_k=\Pi_{i=1}^N \beta_i\text{.}\) On va maintenant conclure à la convergence si \(0 \lt \alpha \lt \frac12\text{,}\) le choix \(\eta_k=\frac{1}{k+1}\) conduit à
Cela permet de conclure la preuve.
En pratique, on utilise une variante du gradient stochastique. En effet le gradient stochastique converge très lentement. Pour cela on utilie à la place le gradient stochastique par mini-batch. L'idée est d'utiliser pas l'ensemble des données pour calculer le gradient, mais un certains nombre tiré aléatoirement.
Algorithm 3.37. Algorithme de descente de gradient stochastique avec mini batch.
On initialise \(\theta_0\)
-
Tant que \(\parallel \nabla_{\theta} \mathcal{J}(\theta_k)\parallel \gt \epsilon\)
on tire aléatoirement \(m\) indice dans \(\left\{1,...,N\right\}\) stockés dans \(I_k\text{,}\)
on calcul \(d_k=\frac{1}{m}\sum_{i\in I_k}^N \nabla_{\theta} j_{i}(\theta_k)\text{,}\)
-
On fait la mise à jour
\begin{equation*} \theta_{k+1}=\theta_k-\eta_k d_k, \end{equation*} on met à jour \(\eta_k\text{.}\)
On renvoie \(\theta_K\text{.}\)