Section 7.1 Processus de décision Markovienne (MDP)
Comme introduit précédemment l'apprentissage par renforcement cherche a contrôler des problème stochastisque par essai/erreur. On va dans un premier temps introduire le cadre mathématique de ces problèmes. Pour cela on va s'inscrire dans le cadre des chaines et processus Markovien.
Subsection 7.1.1 Introduction au MDP
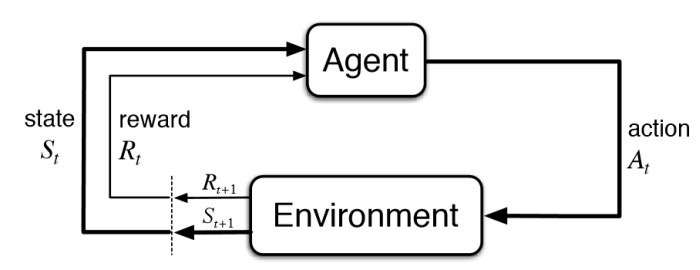
Le cadre des Processus de décision Markovien (MDP) est une théorie permettant de décrire une classe de problèmes de décision. De façon très rapude on peut le décrire comme cela : Nous avons un agent dans un certains \textbf{état}. Cet agent peut réaliser un certains action qui le fera passé de son état a un autre. En utilisant un environnement qui décrit le contexte, l'agent se déplacera dans ce nouvel état et recevra une récompense associée à l'ancien état, au nouvel état et à l'action. Un problème de décision consiste a trouver une stratégie de choix d'action qui va maximiser les récompense. On peut le voir comme un problème d'optimisation. Un processus de décision est définit par le quadruplet \((S,A,P(.),r(.))\text{:}\) \(S\) est l’espace d’états dans lequel évolue le processus ; \(A\) est l’espace des actions qui contrôlent la dynamique de l’état ; \(P(. \mid .,.): S\times A \times S \rightarrow [0,1]\) sont les probabilités de transition entre états; \(r(.,.): S\times A\rightarrow \mathbb{R}\) est la fonction de récompense sur les transitions entre états.
Définition 7.1. Processus de décision Markovien.
L'espace des états et des actions peuvent continus comme discret. Ici on va se restreindre au cas discret et on abordera le cas continue plius tard.
Définition 7.3. Modèle parfait.
Lorsque les probabilités de transition \(P(.\mid .,.)\) et la fonction de récompense sont explicite connus on parle de modèle parfait.
Quand \(r \gt 0\) on parle de récompense et quand \(r \lt 0\) on parle de coût. Sur la figure Figure 7.4 on donne un exemple abstrait de MDP. 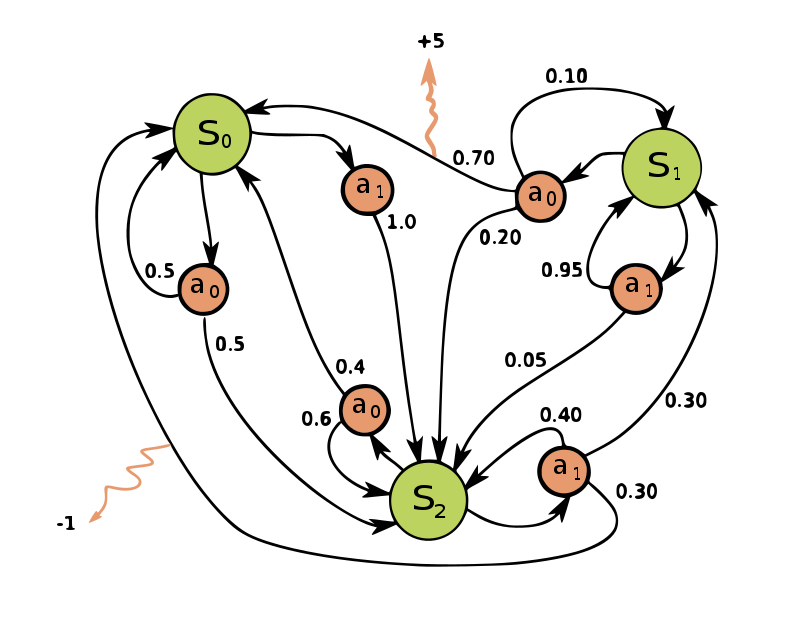
Définition 7.5. Règle de décision Histoire-dépendante.
On nomme une régle de décision histoire-dépendante déterministe une fonction
avec \(h_t=(s_0,a_0,....,s_{t-1},a_{t-1},s_t)\text{.}\) Cette fonction, connaissant un historique, choisie une action. On nomme une régle de décision histoire-dépendante stochastique une loi de probabilité
tel que \(\sum_{a\in A} \pi(a \mid h_t) =1\) qui connaissant un historique renvoit les probabilités de choisir chaque action.
Définition 7.6. Règle de décision.
On nomme une régle de décision Markovienne déterministe une fonction
qui connaissant un état choisie une action. On nomme une politique régle de décision Markovienne stochastique une loi de probabilité
tel que \(\sum_{a\in A} \pi(a \mid s_t) =1\) qui connaissant un état renvoit les probabilités de choisir chaque action.
Les règles de décisions permettent donc de choisir une action a un instant donné en fonction d'un état ou d'un historique. A partir de ces règles de décision locales en temps on peut définir la notion de politique. On nomme une politique stochastique: une ensemble de règles de décision associé à une trajectoire: Cette politique est dite stationnaire si elle ne dépend pas du temps ce qui revient à
Définition 7.7. Politiques et politiques stationnaires.
et la récompense suivant la politique \(\pi\) comme \(r_{\pi}=\sum_{a\in A}\pi(a\mid s)r(s,a)\text{.}\) Ces définitions peuvent être aussi faite dans le cas déterministe avec \(\mathbb{P}^{\pi}(s_{s+1}=s^{'} \mid s_t = s)=P(s^{'} \mid \mu(s),s)\) et \(r_{\pi}=(s,\mu(s))\text{.}\) A partir de la on obtient que le triplet \((S,\mathbb{P}^{\pi},r^{\pi})\) forme une chaine de Markov valuée c'est a dire une chaine de Markov ou les transitions sont pondérés. Si la politique est stationnaire on obtient une chaine de Markov homogène. Pour compléter il faut un critère a optimiser. Dans la liltérature en général trois quantités classiques qu'ont souhaite maximiser. On appelle \(G_t\) les retours. Il s'agit d'une fonction des récompenses à partir du temps \(t\text{.}\) Il s'agit de la quantité a maximiser. Le critère a horizon fini consiste a maximiser: Le critère a horizon amorti consiste a maximiser: avec \(0 \lt \gamma \lt 1\text{.}\) Plus \(\gamma\) est proche de zéro plus le court terme est priviligié. Le critère moyen consiste a maximiser:
Définition 7.8. Retours.
Définition 7.9.
Définition 7.10.
Définition 7.11.
Subsection 7.1.2 Exemples de MDP
Dans cette section on va proposer plusieurs exemples de MDP à la fois déterministe et stochastiques ou le modèle est explicite (modèle parfait) comme inconnu.
Subsubsection 7.1.2.1 Parcours de graphe
Un problème classique en théorie des graphes est le parcours de poid minimal. On par d'un graphe valué et on cherche le plus court chemin au sens des poids. Le noeud initiale n'est pas fixé. Le noeud final est fixé: \(x_f\) On peut naturellement voir comme application les problèmes de trajets routier. Ici on pose \(s_t = x_{current}\) le noeud courant graphe, \(a_t= x_{next}\) le noeud suivant. On a donc $S, A$ l'ensemble des noeuds du graphe. On définit un coût associé a chaque arête qui est donnée par le poid:
et une récompense quand on arrive \(g(s_t)=\chi_{s_t=x_f}\) avec \(\chi\) la fonction indicatrice. On obtient le critère final a optimiser:
On peut imaginer un environement ou les poids chaque dynamiquement en temps (en fonction du trafic). Cela pourrait être modéliser par
avec \(B_t\) un bruit Gaussien.
Subsubsection 7.1.2.2 Maintenance de stock
Le responsable d'un entrepot dispose d'un stock \(s_t\) d'une marchandise qui correspondra a notre état. Il doit satisfaire la demande \(D_t\) des clients qui est modélisé par un processus aléatoire (Poisson ou autre). Pour cela, il peut, tous les mois, décider de commander une quantité \(a_t\) supplémentaire à son fournisseur (action). L'entrepot a une capacité limite \(M\) donc \(A = \left\{0,1,...M-s_t \right\}\) La dynamique est donnée par
L'objectif est de maximisé le profit. Pour modéliser cela on a un coût de stock \(h(s)\) et un coût de commande \(C(a)\) et une fonction de revenu \(f(q)\) qui dépent du stock vendu. On obtient les recompenses:
On fixe un revenu \(g(s)\) pour le stock restant ce qui donne le critère suivant:
Subsubsection 7.1.2.3 Stabilisation d'une EDO/EDS
On se donne une Equation différentielle:
Le but est de conduire ou de stabiliser cette équation autour d'un état \(x_0\text{.}\) On peut imaginer par exemple un problème de trajectoire spatiale. La fonction \(R\) correspond à une commande tel que
Dans ce cas l'etat est donné par \(s_t=x_n\text{,}\) la transition est donnée par
avec \(a^n = R(x^n)\text{.}\) En général on veut limiter la norme du contrôle donc on souhaite maximiser
avec
Subsubsection 7.1.2.4 Optimisation d'un traitement contre le cancer
Dans les traitements du Cancer on utilise des traitement multi-modalité (chirurgie, radiothérapie ou chimiothérapie). L'articulation de ces modalités semble pour moment très dépendante du praticien. L'idée de cet exemple est d'automatiser la construction de ces traitement multi-modélalité par un procéssus de Décision Markovien qu'on va optimiser. Ici il est considéré trois types de traitement:
Modalité 1 (M1): fort risque d'effet sécondaire sur les tissus sains, efficacité importante (fréquence d'utilisation limitée),
Modalité 2 (M2): faible risque d'effet sécondaire sur les tissus sains, efficacité modéré,
Modalité 3 (M3) :pas de traitement, baisse de la probabilité d'effet secondaire, progression de la tumeur plus importante.
On définit un état \(s_{t}=(h_t,\phi_t,\tau_t)$ avec $h_t\in \left\{0,1\right\}\) qui définit l'utilisation de la modalité M1. Si \(h_t=1\) la modalité a déjà été utilisée. \(\phi_t=\left\{0,..,m\right\}\) représente l'effet sur les tissus sains (\(0\) pas d'effet, \(m\) beaucoup d'effet) et \(\tau_t=\left\{0,..,n\right\}\) représente la progréssion de la tumeur (\(0\) rémission, \(n\) décès du patient). L'espace des action est donné par \(a_t\in \left\{ M_1,M_2,M_3\right\}\text{.}\) Pour les probabilité de transition on a:
avec \(P_{t}^H(h_{t+1} \mid h_t, M_1)= 1$, $P_{t}^H(h_{t} \mid h_t, M_2)= 1\) et \(P_{t}^H(h_{t} \mid h_t, M_3)= 1\text{.}\) Pour imposer que la modalité 1 doit être utilisée qu'une seule fois on ajoute:
ce qui veut dire si on réutilise ce traitment on passe directement l'état final (ici la mortalité). On définit 3 états finaux:
\(\displaystyle \phi= m\)
\(\displaystyle \tau = n\)
\(\displaystyle (h,\phi,\tau)=(0,0,0)\)
Exemple de probabilité:
Transition de \(\phi_{t+1}\)
Transition de \(\tau_{t+1}\)
Modalité
\(\phi_t -1\)
\(\phi_t\)
\(\phi_t +1\)
\(\tau_t -1\)
\(\tau_t\)
\(\tau_t +1\)
\(M_1\)
\(0\)
\(0.4\)
\(0.6\)
\(0.7\)
\(0.3\)
\(0\)
\(M_2\)
\(0\)
\(0.6\)
\(0.4\)
\(0.7\)
\(0.3\)
\(0\)
\(M_2\)
\(0.6\)
\(0.4\)
\(0\)
\(0\)
\(0.3\)
\(0.7\)
avec \(d\in \left\{2,\frac32,3\right\}\text{.}\) On peut aussi faire des récompenses à chaque temps \(t\text{.}\) C'est probablement pas réaliste car on ne mesure pas aussi souvent.
Subsubsection 7.1.2.5 Contrôle d'épidémie
La simulation d'épidemie est classiquement réalisée par des ODE comme dans l'exemple 3. Cependant ppur modéliser des épidémies avec une structure de contacts très hétérogènes. On pense, par exemple, au Sars-cov2 avec les super-contaminateurs. Pour cela on utilise des méthodes "individu-centré". Pour cela on définit un graphe ou chaque noeud représente un individu et chaque arête represente un contact. Les individus sont soit suceptible 'S', infecté 'I' ou retiré 'R'. Chaque jour, chaque individu infecté a une probabilité de contaminer une personne saine et a une certaine probabilité de devenir retiré. 
Subsubsection 7.1.2.6 Jeux et Robotique
Les deux grosses application actuelles sont les jeux et la robotique. Pour le jeux type echec ou go il s'agit d'une problème de type MDP avec connaissance du modèle (modèle parfait). Cependant il s'agit de gros problèmes ou le nombre total d'états devient très grand/ L'apprentissage des robots est évidemment une application naturelle de l'apprentissage par renforcement. Ici l'agent est le robot, et l'environnement peut être vu comme une boite noir auquel on a pas vraiment accès et donc on ne peut pas obtenir de modèle parfait.