Section 5.5 Auto-encoder et réduction de dimension
Subsection 5.5.1 Principe de l'auto-encodeur
Comme précédemment on suppose qu'on a des données \((x_1,..x_n)\) de \(\mathbb{R}^d\) et qu'on peut les approcher de la façon suivante:
avec \(m \lt \lt d\) et \(D\) une fonction non linéaire. L'enjeu est donc de trouver les la représentation \(z\) et de trouver l'opérateur \(D\text{.}\) L'idée central des auto-encodeurs est de trouver \(z\) à partir d'une transformation de \(x\) et de construire cette transformation ainsi qu'une approximation de \(D\) en même temps.
Définition 5.62.
Soit \(X\subset \mathbb{R}^d\) et \(Z\subset \mathbf{R}^m\) avec \(m \lt d\text{.}\) On nomme encodeur une fonction paramétrique \(E_{\theta_e}: X \rightarrow Z\) et on nomme décodeur une fonction paramétrique \(D_{\theta_d}: Z \rightarrow X\text{.}\)
Définition 5.63.
Soit \((x_1,..x_n)\) de \(\mathbb{R}^d\text{.}\) On nomme auto-encodeur un couple encodeur-décodeur solution du problème de minimisation:
avec \(R\) un terme de régularisation.
L'idée d'un auto-encodeur est donc d'apprendre un opérateur de compression et un opérateur de compression en même temps de façon a ce que la composition des deux soit le plus proche possible de l'identité. Évidemment si \(m\) n'est pas inférieur a \(d\) donc si il n'y pas de perte d'information la solution sera l'identité. Mais dans le cas ou \(m \lt d\) on va avoir de la perte d'information lors de la compression et donc ne pourra pas apprendre l'identité. Dans ce formalisme on peut utiliser n'importe quel modèle paramétrique. On peut montrer qu'en prenant un modèle linéaire pour l'encodeur et le décodeur la solution du problème est donnée par la solution de la PCA. L'idée ici est évidemment d'utiliser des réseaux de neurones pour approcher des transformations nonlinéaires. Les méthodes d'apprentissage de variété calculaient pour les \(x_i\) du jeux l'apprentissage les \(z_i\) et ne fournissait pas d'opérateur \(E\) et \(D\text{.}\) Il fallait compléter cela par la méthode de Neystrom ou une méthode de régression. Ici par construction on définit naturellement les deux opérateurs. 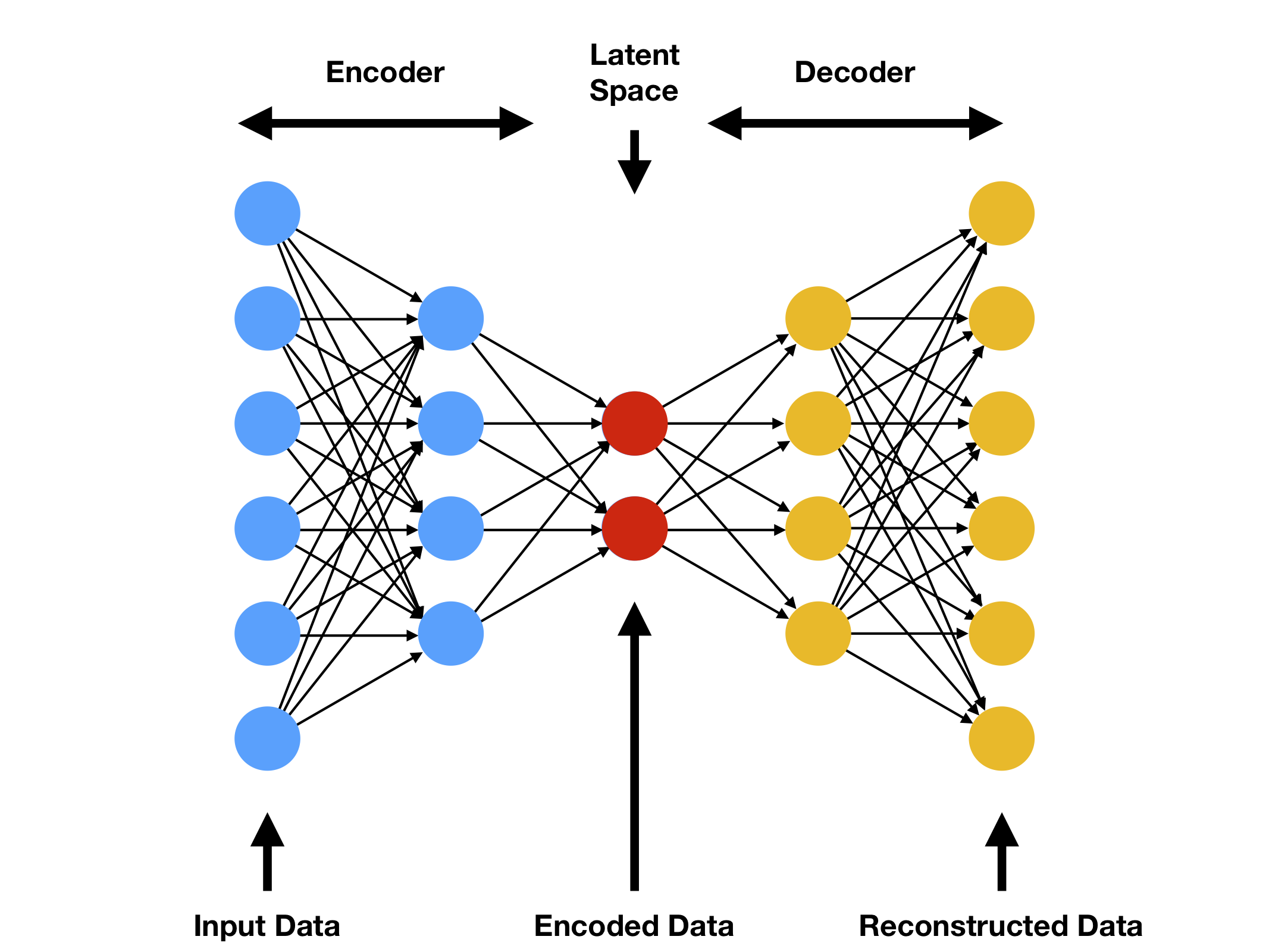
Subsection 5.5.2 Auto-encoder convolutif
Dans le cas de données structurées sur une grille on souhaiterait tirer parti des réseaux convolutifs dans ce genre de cas. Dans ce cas l'idée est d'enchaîner des couches de convolutions avec des couches de pooling (qui diminue la taille du signal). Cependant diminuer la dimension uniquement en divisant par deux la taille du signal peut générer des réseaux assez profonds ou ne pas atteindre une taille cible en dimension réduite. Pour éviter cela au bout d'un certain nombre de blocs: convolution-pooling on applique une couche "flatten" et on enchaîne des couches totalement connectées qui vont aussi baissé la dimension. Le décodeur est construit de façon symétrique. C'est schématisé sur l'image Figure 5.65. 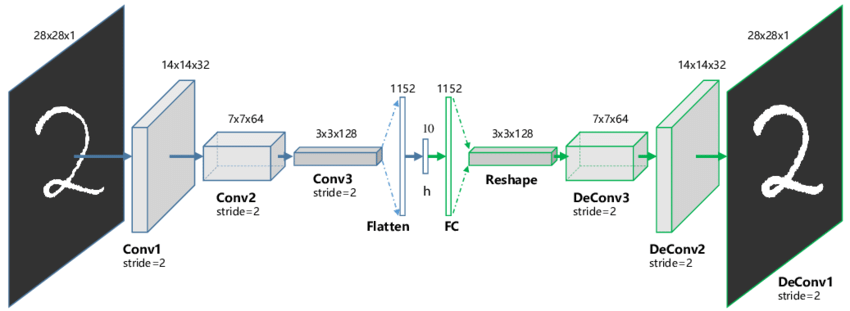
Subsection 5.5.3 Espace lalent et variantes des AE
Soit des données \(x\in X \subset \mathbb{R}^d\text{.}\) On se donne un encoder et une décodeur tel que et L'espace \(Z\) est appelé l'espace latent.
Définition 5.66.
Des méthodes de compression linéaires comme l'ACP génèrent des espaces latents avec des propriétés intéressantes. Les vecteurs de bases dans l'espace réduit sont orthogonales. De plus les vecteurs de bases sont ordonnés en fonction de leurs capacités de représentation (on peut interpréter cela comme une base spectrale ou plus on ajoute des modes plus on ajoute des détails associés aux hautes fréquences). Puisque les auto-encodeurs sont des méthodes nonlinéaires, elles permettent une meilleure compression que les méthodes linéaires comme l'ACP. Mais l'espace latent est plus difficile interprétable (on ne connaît pas les variables dominantes) et on ne peut pas exclure que certaines variables soient corrélées entre elles.
Une première approche pour introduire de la structure dans l'espace latent a été d'introduire de la parcimonie dans la représentation latente. On parle d'autoencodeur parcimonieux. Un auto-encodeur \(k\) parcimonieux est un auto-encodeur ou on modifie la dernière couche de l'encodeur. Si l'avant-dernière couche génère une donnée à de dimension \(m\text{:}\) \(x=(x_1,...,x_m)\) on ajoute comme fonction d'activation de cette couche: avec \(b_i=1\) si \(\mid x_i\mid\) est un des k plus grands module et \(b_i=0\) sinon. Un auto-encodeur parcimonieux à \(K\) couche utilise la fonction de coût Définition 5.63 avec la régularisation suivante: avec \(w_k\) des poids, \(s\) une fonction comme \(r(x,y)=\mid x-y \mid^p\) avec \(\rho_k(x)\) un indicateur de la parcimonie de la couche \(k\) définie par avec \(\sigma_{k,j}\) la fonction d'activation de la couche \(k\) et du neurone \(j\text{.}\) La quantité \(\hat{\rho}_k\) correspond à la parcimonie visée pour une couche donnée. Un auto-encodeur parcimonieux à \(K\) couche utilise la fonction de coût Définition 5.63 avec la régularisation suivante: avec \(h_k\) le vecteur issu de la couche \(k\text{.}\) Un auto-encodeur contractante utilise la fonction de coût Définition 5.63 avec la régularisation suivante: avec \(\parallel.\parallel_F^2\) la norme de Frobinus.
Définition 5.67. Autoencodeur k-parcimonieux.
Définition 5.68. Régularisation parcimonieuse I.
Définition 5.69. Régularisation parcimonieuse II.
Définition 5.70. Régularisation contractante.
Subsubsection 5.5.3.1 Auto-encodeur ACP
L'idée de cette approche va être de construire l'espace latent en augmentant progressivement la taille de celui-ci et en minimisation les corrélations entre les variables latentes. On se fixe une famille d'auto-encoder \(E_{\theta_k}(x)\) de poids \(\theta_k\text{.}\) Si on se donne un jeu de données \((x_1,....x_n)\in \mathbb{R}^n\) notre objectif est de construire les variables latentes: \((z_1,....z_n)\in \mathbb{R}^d\text{.}\) Si on se donne deux composantes d'une données latente \(z_i\) noté \(z_i^1\) et \(z_i^2\) la covariance entre ses deux composantes associées aux jeux de données est définie par Si les données sont de moyenne nulle ce la revient à Un auto-encodeur ACP est constitué d'une série d'encodeurs \(E_{\theta_1},....,E_{\theta_K}\) et d'un décodeur \(D\text{.}\) On entraîne les encodeurs un par un et on réentraîne le décodeur à chaque fois. Pour cela on minimise à l'itération \(k\text{:}\) avec
Définition 5.71.
Définition 5.72. Auto-encodeur ACP.